Html2Article
.NET平台下,一个高效的从Html中提取正文的工具。
正文提取采用了基于文本密度的提取算法,支持从压缩的Html文档中提取正文,每个页面平均提取时间为30ms,正确率在95%以上。
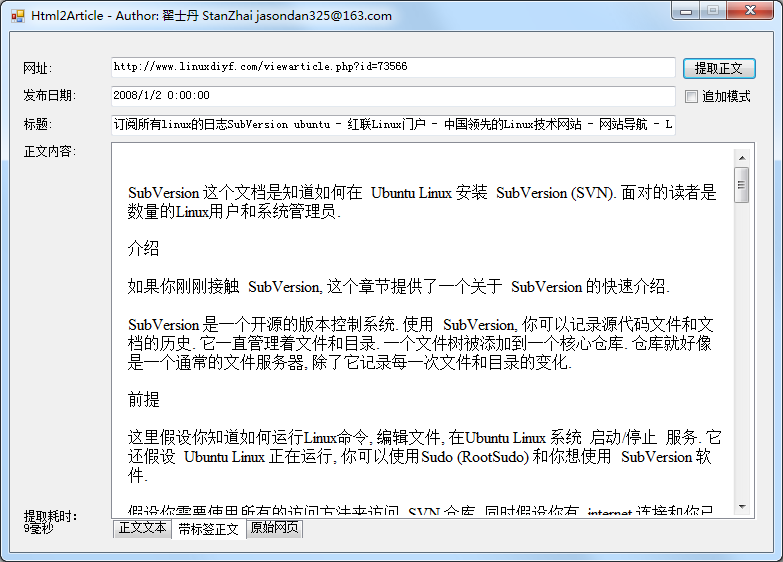
Html2Article特色
- 标签无关,提取正文不依赖标签;
- 支持从压缩的html文档中提取正文内容;
- 支持带标签输出原始正文;
- 核心算法简洁高效,平均提取时间在30ms左右。
让你的项目支持Html正文提取
PM> Install-Package Html2Article- 引入命名空间
using StanSoft;。 - 添加如下代码:
// html为你要提取的html文本
string html = "<html>....</html>";
// article对象包含Title(标题),PublishDate(发布日期),Content(正文)和ContentWithTags(带标签正文)四个属性
Article article = Html2Article.GetArticle(html);Html2Article类
- Html2Article类是提取正文的核心类
-
Html2Article配置说明
- AppendMode:是否使用正文追加模式,默认为false,设置为true会将更多符合条件的文本添加到正文。
- Depth:分析的深度,默认为5,对于行空隙较大的页面可增加此值。
- LimitCount:字符限定数,当分析的文本数量达到限定数则认为进入正文内容,默认为180个字符。
- GetArticle(string html):从Html文本中获取Article。
