DataCost
Calculate cost based metrics about data based on the number of positive and negative data points.
These cost metrics are used at the core of the classification algorithms CSTree, CSForest, BCSForest, and BCF. The functions have been carefully implemented following a TDD style and auto-generated documentation is available in the documentation folder.
Basic Notation Used in this Readme
- NTN: Number of true negative predictions.
- NTP: Number of true positive predictions.
- NFN: Number of false negative predictions.
- NFP: Number of false positive predictions.
- CTN: Cost incurred by true negative predictions.
- CTP: Cost incurred by true positive predictions.
- CFN: Cost incurred by false negative predictions.
- CFP: Cost incurred by false positive predictions.
What Can Be Calculated Using datacost:
Cost of Labelling a Set of Data Points as Either Negative or Positive
The cost incurred by labelling as negative is calculated as:
CN = NTN X CTN + NFN X CFN
The cost incurred by labelling as positive is calculated as:
CP = NTP X CTP + NFP X CFP
Expected Cost
The expected cost is typically a representation of how much a set of data points can be expected to cost a business. It is represented by the symbol E. The equation for E is as follows:
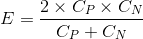
Expected Cost After Split
After a split, a set of data points has several new sets of class supports, one for each split. The expected cost difference can be calculated as the difference between E for the original dataset, and the summed E over all splits. The equation for expected cost after a split is as follows:
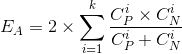
Where k is the number of splits, CPi is the value of CP for the i'th split.
Expected Cost Per Record
The expected cost per data point is simply the expected cost for a dataset divided by the number of data points in the dataset. It is a way of normalizing expected cost such that logical comparisons may be made between the expected cost of two datasets of different size.
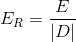
Where |D| is the number of records in the dataset D.
Total Cost
The total cost for a set of records is calculated as either CN or CP, whichever is lowest.
CT = min(CN, CP)
