MultiprocessingSpider
Description
MultiprocessingSpider is a simple and easy-to-use web crawling and web scraping framework.
Architecture
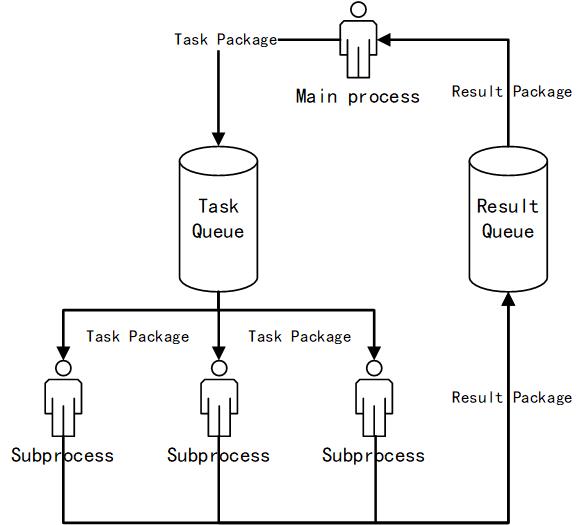
Dependencies
- requests
Installation
pip install MultiprocessingSpider
Basic Usage
MultiprocessingSpider
from MultiprocessingSpider.spiders import MultiprocessingSpider
from MultiprocessingSpider.packages import TaskPackage, ResultPackage
class MyResultPackage(ResultPackage):
def __init__(self, prop1, prop2, sleep=True):
super().__init__(sleep)
self.prop1 = prop1
self.prop2 = prop2
class MySpider(MultiprocessingSpider):
start_urls = ['https://www.a.com/page1']
proxies = [
{"http": "http://111.111.111.111:80"},
{"http": "http://123.123.123.123:8080"}
]
def router(self, url):
return self.parse
def parse(self, response):
# Parsing task or new page from "response"
...
# Yield a task package
yield TaskPackage('https://www.a.com/task1')
...
# Yield a url or a url list
yield 'https://www.a.com/page2'
...
yield ['https://www.a.com/page3', 'https://www.a.com/page4']
@classmethod
def subprocess_handler(cls, package, sleep_time, timeout, retry):
url = package.url
# Request "url" and parse data
...
# Return result package
return MyResultPackage('value1', 'value2')
@staticmethod
def process_result_package(package):
# Processing result package
if 'value1' == package.prop1:
return package
else:
return None
if __name__ == '__main__':
s = MySpider()
# Start the spider
s.start()
# Block current process
s.join()
# Export results to csv file
s.to_csv('result.csv')
# Export results to json file
s.to_json('result.json')FileSpider
from MultiprocessingSpider.spiders import FileSpider
from MultiprocessingSpider.packages import FilePackage
class MySpider(FileSpider):
start_urls = ['https://www.a.com/page1']
stream = True
buffer_size = 1024
overwrite = False
def router(self, url):
return self.parse
def parse(self, response):
# Parsing task or new page from "response"
...
# Yield a file package
yield FilePackage('https://www.a.com/file.png', 'file.png')
...
# Yield a new url or a url list
yield 'https://www.a.com/page2'
...
yield ['https://www.a.com/page3', 'https://www.a.com/page4']
if __name__ == '__main__':
s = MySpider()
# Add a url
s.add_url('https://www.a.com/page5')
# Start the spider
s.start()
# Block current process
s.join()FileDownloader
from MultiprocessingSpider.spiders import FileDownloader
if __name__ == '__main__':
d = FileDownloader()
# Start the downloader
d.start()
# Add a file
d.add_file('https://www.a.com/file.png', 'file.png')
# Block current process
d.join()License
GPLv3.0
This is a free library, anyone is welcome to modify : )
