Graph Transliterator




A graph-based transliteration tool that lets you convert the symbols of one language or script to those of another using rules that you define.
- Free software: MIT license
- Documentation: https://graphtransliterator.readthedocs.io
- Repository: https://github.com/seanpue/graphtransliterator
Transliteration... What? Why?
Moving text or data from one script or encoding to another is a common problem:
- Many languages are written in multiple scripts, and many people can only read one of them. Moving between them can be a complex but necessary task in order to make texts accessible.
- The identification of names and locations, as well as machine translation, benefit from transliteration.
- Library systems often require metadata be in particular forms of romanization in addition to the original script.
- Linguists need to move between different methods of phonetic transcription.
- Documents in legacy fonts must now be converted to contemporary Unicode ones.
- Complex-script languages are frequently approached in natural language processing and in digital humanities research through transliteration, as it provides disambiguating information about pronunciation, morphological boundaries, and unwritten elements not present in the original script.
Graph Transliterator abstracts transliteration, offering an "easy reading" method for developing transliterators that does not require writing a complex program. It also contains bundled transliterators that are rigorously tested. These can be expanded to handle many transliteration tasks.
Contributions are very welcome!
Features
- Provides a transliteration tool that can be configured to convert the tokens
of an input string into an output string using:
- user-defined types of input tokens and token classes
-
transliteration rules based on:
- a sequence of input tokens
- specific input tokens that precede or follow the token sequence
- classes of input tokens preceding or following specified tokens
- "on match" rules for output to be inserted between transliteration rules involving particular token classes
- defined rules for whitespace, including its optional consolidation
- Can be setup using:
- Automatically orders rules by the number of tokens in a transliteration rule
- Checks for ambiguity in transliteration rules
- Can provide details about each transliteration rule match
- Allows optional matching of all possible rules in a particular location
- Permits pruning of rules with certain productions
- Validates, as well as serializes to and deserializes from JSON and Python data types, using accessible marshmallow schemas
- Provides full support for Unicode, including Unicode character names in the "easy reading" YAML format
- Constructs and uses a directed tree and performs a best-first search to find the most specific transliteration rule in a given context
- Includes bundled transliterators that you can add to hat check for full test coverage of the nodes and edges of the internal graph and any "on match" rules
- Includes a command-line interface to perform transliteration and other tasks
Sample Code and Graph
from graphtransliterator import GraphTransliterator
GraphTransliterator.from_yaml("""
tokens:
h: [consonant]
i: [vowel]
" ": [whitespace]
rules:
h: \N{LATIN SMALL LETTER TURNED I}
i: \N{LATIN SMALL LETTER TURNED H}
<whitespace> i: \N{LATIN CAPITAL LETTER TURNED H}
(<whitespace> h) i: \N{LATIN SMALL LETTER TURNED H}!
onmatch_rules:
- <whitespace> + <consonant>: ¡
whitespace:
default: " "
consolidate: true
token_class: whitespace
metadata:
title: "Upside Down Greeting Transliterator"
version: "1.0.0"
""").transliterate("hi")'¡ᴉɥ!'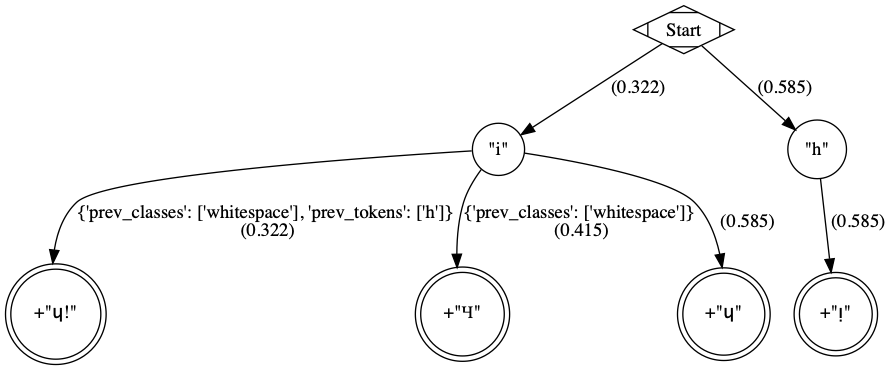
Sample directed tree created by Graph Transliterator. The rule nodes are in double circles, and token nodes are single circles. The numbers are the cost of the particular edge, and less costly edges are searched first. Previous token classes and previous tokens that must be present are found as constraints on the edges incident to the terminal leaf rule nodes.
Get It Now
$ pip install -U graphtransliteratorCitation
To cite Graph Transliterator, please use:
Pue, A. Sean (2019). Graph Transliterator: A graph-based transliteration tool. Journal of Open Source Software, 4(44), 1717, https://doi.org/10.21105/joss.01717


