GuwenCOMBO
Tokenizer, POS-Tagger, and Dependency-Parser for Classical Chinese Texts (漢文/文言文), working with COMBO-pytorch.
Basic usage
>>> import guwencombo
>>> lzh=guwencombo.load()
>>> s=lzh("不入虎穴不得虎子")
>>> print(s)
# text = 不入虎穴不得虎子
1 不 不 ADV v,副詞,否定,無界 Polarity=Neg 2 advmod _ Gloss=not|SpaceAfter=No
2 入 入 VERB v,動詞,行為,移動 _ 0 root _ Gloss=enter|SpaceAfter=No
3 虎 虎 NOUN n,名詞,主体,動物 _ 4 nmod _ Gloss=tiger|SpaceAfter=No
4 穴 穴 NOUN n,名詞,固定物,地形 Case=Loc 2 obj _ Gloss=cave|SpaceAfter=No
5 不 不 ADV v,副詞,否定,無界 Polarity=Neg 6 advmod _ Gloss=not|SpaceAfter=No
6 得 得 VERB v,動詞,行為,得失 _ 2 parataxis _ Gloss=get|SpaceAfter=No
7 虎 虎 NOUN n,名詞,主体,動物 _ 8 nmod _ Gloss=tiger|SpaceAfter=No
8 子 子 NOUN n,名詞,人,関係 _ 6 obj _ Gloss=child|SpaceAfter=No
>>> t=s[1]
>>> print(t.id,t.form,t.lemma,t.upos,t.xpos,t.feats,t.head.id,t.deprel,t.deps,t.misc)
1 不 不 ADV v,副詞,否定,無界 Polarity=Neg 2 advmod _ Gloss=not|SpaceAfter=No
>>> print(s.to_tree())
不 <════╗ advmod
入 ═══╗═╝═╗ root
虎 <╗ ║ ║ nmod
穴 ═╝<╝ ║ obj
不 <════╗ ║ advmod
得 ═══╗═╝<╝ parataxis
虎 <╗ ║ nmod
子 ═╝<╝ obj
>>> f=open("trial.svg","w")
>>> f.write(s.to_svg())
>>> f.close()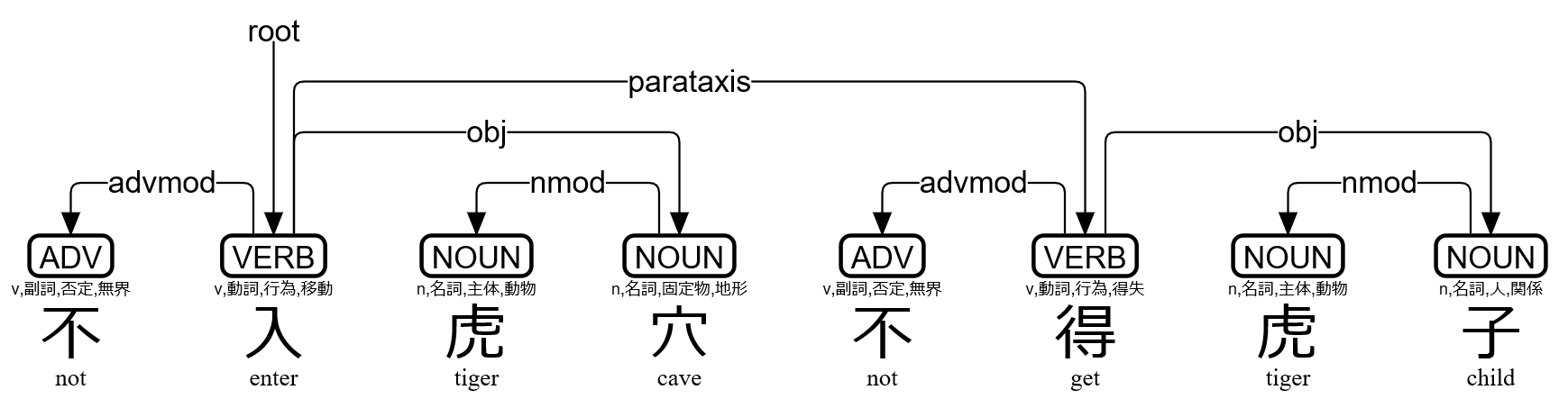
guwencombo.load() has two options guwencombo.load(BERT="guwenbert-base",Danku=False). With the option BERT="guwenbert-large" the pipeline utilizes GuwenBERT-large. With the option Danku=True the pipeline tries to segment sentences automatically. to_tree() and to_svg() are borrowed from those of UD-Kanbun.
Kundoku usage
>>> import guwencombo
>>> lzh=guwencombo.load()
>>> s=lzh("不入虎穴不得虎子")
>>> t=guwencombo.translate(s)
>>> print(t)
# text = 虎の穴に入らずして虎の子を得ず
1 虎 虎 NOUN n,名詞,主体,動物 _ 3 nmod _ Gloss=tiger|SpaceAfter=No
2 の _ ADP _ _ 1 case _ SpaceAfter=No
3 穴 穴 NOUN n,名詞,固定物,地形 Case=Loc 5 obj _ Gloss=cave|SpaceAfter=No
4 に _ ADP _ _ 3 case _ SpaceAfter=No
5 入ら 入 VERB v,動詞,行為,移動 _ 0 root _ Gloss=enter|SpaceAfter=No
6 ずして 不 AUX v,副詞,否定,無界 Polarity=Neg 5 advmod _ Gloss=not|SpaceAfter=No
7 虎 虎 NOUN n,名詞,主体,動物 _ 9 nmod _ Gloss=tiger|SpaceAfter=No
8 の _ ADP _ _ 7 case _ SpaceAfter=No
9 子 子 NOUN n,名詞,人,関係 _ 11 obj _ Gloss=child|SpaceAfter=No
10 を _ ADP _ _ 9 case _ SpaceAfter=No
11 得 得 VERB v,動詞,行為,得失 _ 5 parataxis _ Gloss=get|SpaceAfter=No
12 ず 不 AUX v,副詞,否定,無界 Polarity=Neg 11 advmod _ Gloss=not|SpaceAfter=No
>>> print(t.sentence())
虎の穴に入らずして虎の子を得ず
>>> print(s.kaeriten())
不㆑入㆓虎穴㆒不㆑得㆓虎子㆒
>>> print(t.to_tree())
虎 ═╗<╗ nmod(体言による連体修飾語)
の <╝ ║ case(格表示)
穴 ═╗═╝<╗ obj(目的語)
に <╝ ║ case(格表示)
入 ═╗═══╝═╗ root(親)
ら ║ ║
ず <╝ ║ advmod(連用修飾語)
し ║
て ║
虎 ═╗<╗ ║ nmod(体言による連体修飾語)
の <╝ ║ ║ case(格表示)
子 ═╗═╝<╗ ║ obj(目的語)
を <╝ ║ ║ case(格表示)
得 ═╗═══╝<╝ parataxis(隣接表現)
ず <╝ advmod(連用修飾語)translate() and reorder() are borrowed from those of UD-Kundoku.
Installation for Linux
pip3 install guwencomboInstallation for Cygwin64
Make sure to get python37-devel python37-pip python37-cython python37-numpy python37-cffi gcc-g++ mingw64-x86_64-gcc-g++ gcc-fortran git curl make cmake libopenblas liblapack-devel libhdf5-devel libfreetype-devel libuv-devel packages, and then:
curl -L https://raw.githubusercontent.com/KoichiYasuoka/UniDic-COMBO/master/cygwin64.sh | sh
pip3.7 install guwencomboInstallation for macOS
g++ --version
pip3 install guwencombo --user
python3 -m spacy download en_core_web_sm --userIf you fail to install Jsonnet, try below before installing GuwenCOMBO:
( echo '#! /bin/sh' ; echo 'exec gcc `echo $* | sed "s/-arch [^ ]*//g"`' ) > /tmp/clang
chmod 755 /tmp/clang
env PATH="/tmp:$PATH" pip3 install jsonnet --userIf you fail to install fugashi, try to install MeCab before installing GuwenCOMBO:
cd /tmp
git clone --depth=1 https://github.com/taku910/mecab
cd mecab/mecab
./configure --with-charset=UTF8
make && sudo make installReference
- 安岡孝一: TransformersのBERTは共通テスト『国語』を係り受け解析する夢を見るか, 東洋学へのコンピュータ利用, 第33回研究セミナー (2021年3月5日), pp.3-34.
