False Discovery Rate Smoothing (smoothfdr)
The smoothfdr package provides an empirical-Bayes method for exploiting spatial structure in large multiple-testing problems. FDR smoothing automatically finds spatially localized regions of significant test statistics. It then relaxes the threshold of statistical significance within these regions, and tightens it elsewhere, in a manner that controls the overall false-discovery rate at a given level. This results in increased power and cleaner spatial separation of signals from noise. It tends to detect patterns that are much more biologically plausible than those detected by existing FDR-controlling methods.
For a detailed description of how FDR smoothing works, see the paper on arXiv.
Installation
To install the Python version:
pip install smoothfdr
You can then run the tool directly from the terminal by typing the smoothfdr command. If you want to integrate it into your code, you can simply import smoothfdr.
The R source and package will be on CRAN and available publicly soon.
Running an example
There are lots of parameters that you can play with if you so choose, but one of the biggest benefit of FDR smoothing is that you don't have to worry about it in most cases.
To run a simple example, we can generate our own synthetic data:
gen2d example/data.csv example/true_weights.csv example/true_signals.csv example/oracle_posteriors.csv example/edges.csv example/trails.csv --signal_dist_name alt1 --plot example/data.png
The above command generates a dataset of 128x128 test sites arranged along a grid, with spatial dependence between adjacent neighbors. The true prior probability of sampling from the null distribution and an example of the realized values is below:
Visualizations of the true priors and raw data
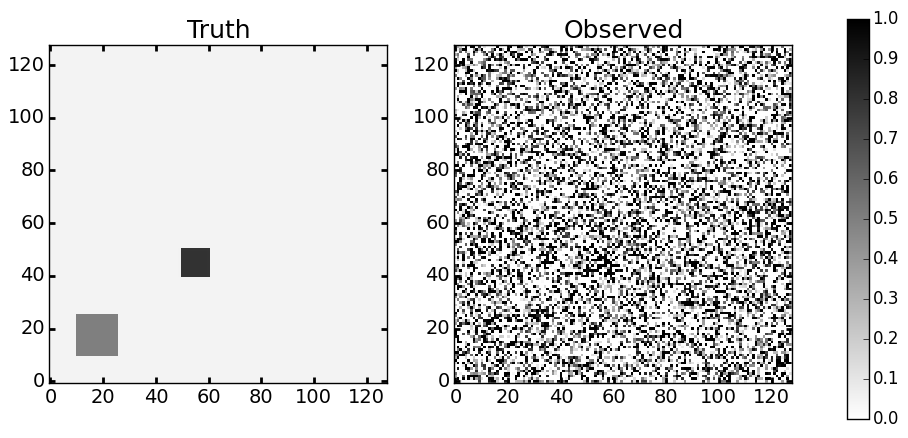
Given this dataset, we can now run the FDR smoothing algorithm to try and estimate the true prior regions and improve the power of our hypothesis tests:
smoothfdr --data_file example/data.csv --no_data_header \
--empirical_null --estimate_signal --solution_path --dual_solver graph \
--save_weights example/sfdr_weights.csv \
--save_posteriors example/sfdr_posteriors.csv \
--save_plateaus example/sfdr_plateaus.csv \
--save_signal example/sfdr_estimated_signal.csv \
--save_discoveries example/sfdr_discoveries.csv \
--plot_path example/solution_path.png \
--verbose 1 \
graph --trails example/trails.csv
The first line simply feeds in the data and specifies there is no header line in the data file. The second line specifies the details of the FDR smoothing run-- we want to empirically estimate the null (as opposed to assuming a standard normal), estimate the alternative hypothesis distribution, automatically tune the hyperparameters by evaluating an entire solution path of possible values, and we want to use the fast graph-based fused lasso solver.
This last part is then specified further in the last line by saying our data is aranged as an arbitrary graph and trails have been created already. Trails were created automatically for us in gen2d; if you want to create your own trails for your specific dataset, you can use the trails command-line call from the pygfl package, which is automatically installed as part of the smoothfdr package.
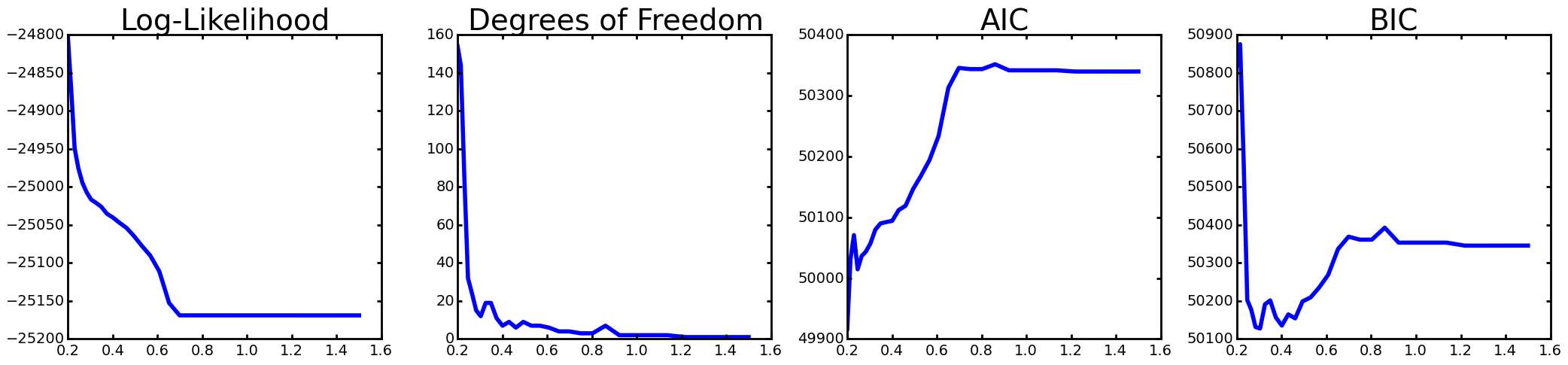
Solution path diagnostics
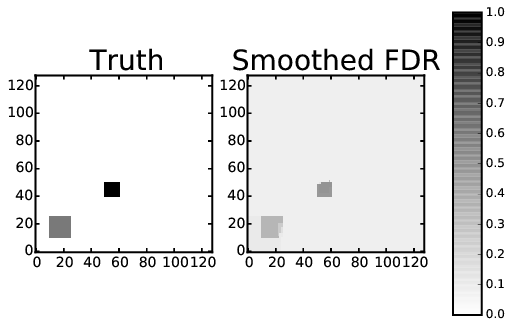
Resulting plateaus detected
For a detailed list of commands, just run smoothfdr -h.
TODO
The package should be fully functional at the moment, however, a few things could be improved:
The predictive recursion function is currently pretty slow due to being a pure python implementation. That will soon be replaced by a C implementation which will be released as another package and incorporated into this one in a future update.
The trail creation is a bit awkward and probably should be automated. In practice, it probably isn't a big deal if your trails are super optimal, so just using the default trail decomposition algorithm in
pygflshould be fine.The plotting could be improved. Currently, you have to run using the slower 2d or 3d solver in order to plot some of the results. That all needs to be replaced and in general the commandline interface should be streamlined to just work with generic graphs. This was mainly due historical progress of finding increasingly more efficient solutions to the optimization problem and wanting to be able to benchmark all of them. At this point it seems clear that the trail-based solver is the fastest and most robust, so it should just be the only solver in the package.

