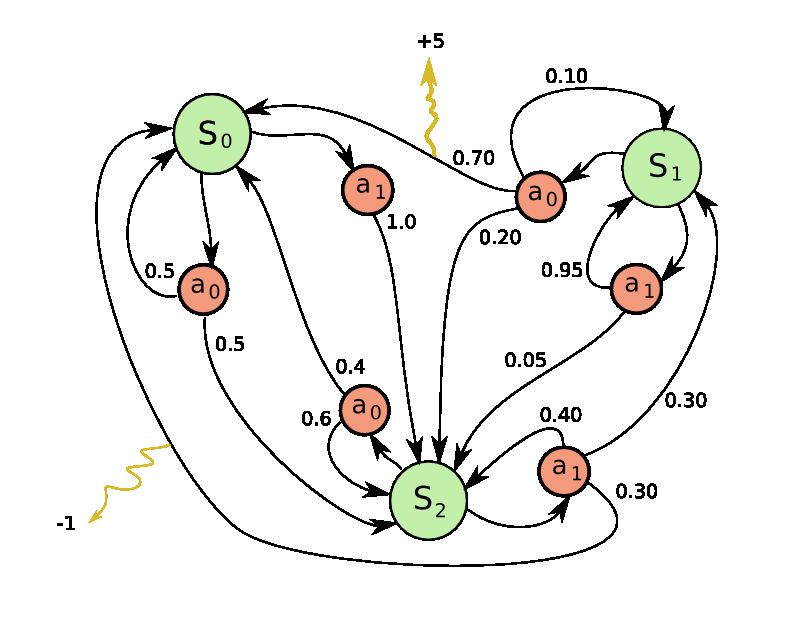
Markov: Simple Python Library for Markov Decision Processes
Author: Stephen Offer
Markov is an easy to use collection of functions and objects to create MDP functions.
Markov allows for synchronous and asynchronous execution to experiment with the performance advantages of distributed systems.
States:
- Reward, Terminal State, Actions, Value, Previous States, Next States, State Policy Probabilities.
Policies:
- Greedy Policy
- e-Greedy Policy
- More to come...
Algorithms:
- Dynamic Programming
- Linear coming soon
Optimizers:
- Value/Policy Iteration
- More to come...
Environments:
- Gridworld (ASCII, PyGame coming soon)
- Gym coming soon
- More to come...
Example:
import numpy as np
import argparse
from markov import GreedyPolicy
from markov.envs.gridworld import GridWorld
def value_iteration(K=1,discount_factor=1.):
env = GridWorld()
P = GreedyPolicy(env)
values = np.zeros(env.n_states)
for k in range(K):
for state in env.states:
v = 0
for i, action in enumerate(state.actions):
policy = state.policy[i]
next_state = action(env, state.action_args)
r = next_state.reward
v += policy * (r + discount_factor * next_state.value)
values[state.index] = v
for state in env.states:
state.value = values[state.index]
env.print()
def main():
parser = argparse.ArgumentParser()
parser.add_argument("--k", help="number of k-iterations",
type=int,default=1)
args = parser.parse_args()
k = args.k
value_iteration(k)
if __name__ == "__main__":
main()
