mlpl
A machine learning pipeline to speed up data science lifecycle.
Using this library, you can:
- Test new experiments easily and keep track of their results.
- Keep details of each preprocessing/FE step easily accessible in collapsibles.
- Do hyperparameter search. (Bayesian search, quick linear search)
- Create a pipeline that consists of useful steps and save/load it.
- Automatically try different processing steps and use useful ones. (imputations, binning, one-hot encoding, ...)
- Make your predictions more reliable by averaging results obtained from different CV splits and random seeds.
Install:
pip install mlpl
Start a new pipeline
A pipeline consists of a class and its config and log files. A pipeline will save your baseline model and the data after the baseline. For trying new steps, it will load the data from its last state. It will also automatically compare results of new steps to that of the baseline. After each useful step, final form of the dataset and hparams will be saved.
Hyperparameter search Pipeline will conduct bayesian/random search for the baseline. For new steps after that, a simple hyperparameter search will take place.
(The reason for that is you cannot conduct a bayesian search for each experiment. However, adding a new step will usually change the ideal hyperparameters, so doing some hyperparameter search is required. Approach in this project is to conduct a bayesian search for the baseline, which will take a lot of time. For testing new steps, a custom simple hyperparameter search method will be used.)
create new pipeline: (example: Titanic competition from Kaggle)
label_name = 'Survived'
trn_path = 'data/train.csv'
test_path = 'data/test.csv'
# Pipeline class will keep track of your processed files, model metrics and experiments.
lr_pipeline = pipe.Pipeline(label_name = label_name,
overwrite = True,
project_path = 'lr_pipeline',
train_data_path = trn_path,
test_data_path = test_path,
minimize_metric = False,
useful_limit = 0.001,
line_search_iter = 1,
n_random_seeds = 1,
bayesian_search_iter= 50,
bayesian_search_count = 1,
final_bayesian_search_iter = 0,
line_search_patience = 2,
line_search_params = {'C': (1e-7, 1e3)})Hyperparameter search using hyperopt
- Specify hyperameter search space for each model.
Search is conducted on parameters in search space. Fixed parameters are parameters that define the model.
This is an example for logistic regression. fixed parameters:
fixed_params_lr = dict(score=accuracy_score,
model=sklearn.linear_model.LogisticRegression,
max_iter=5000,
verbose = 0,
n_jobs = 3,
model_type = 'linear',
folds=[KFold(n_splits= 5, shuffle = True, random_state = 42),
KFold(n_splits= 5, shuffle = True, random_state = 13),
KFold(n_splits= 5, shuffle = True, random_state = 100)])search space:
lr_search_space = dict(C = hp.loguniform('C', -7, 3),
class_weight = hp.choice('class_weight', ['balanced', None]),
solver = hp.choice('solver ', ['lbfgs', 'sag']))Averaging results over different splits
By specifying multiple sklearn folds objects, average predictions over different splits. (Also available for random_state parameters for models.)
folds=[KFold(n_splits= 5, shuffle = True, random_state = 42),
KFold(n_splits= 5, shuffle = True, random_state = 13),
KFold(n_splits= 5, shuffle = True, random_state = 100)]Creating a baseline model
A baseline step is a step with minimal processing. Preprocessing steps and feature engineering steps in the project will be tested against the metrics of baseline model.
create the baseline step:
lr_pipeline.set_baseline_step(model = pmodels.train_sklearn_pipeline,
proc = pdefaults.default_sklearn_preprocess,
search_model_params= lr_search_space,
fixed_model_params = fixed_params_lr
)Run baseline step
res = lr_pipeline.run_baseline(return_result = True)- Output contains a javascript that hides details about the step in collapsible boxes.
output:

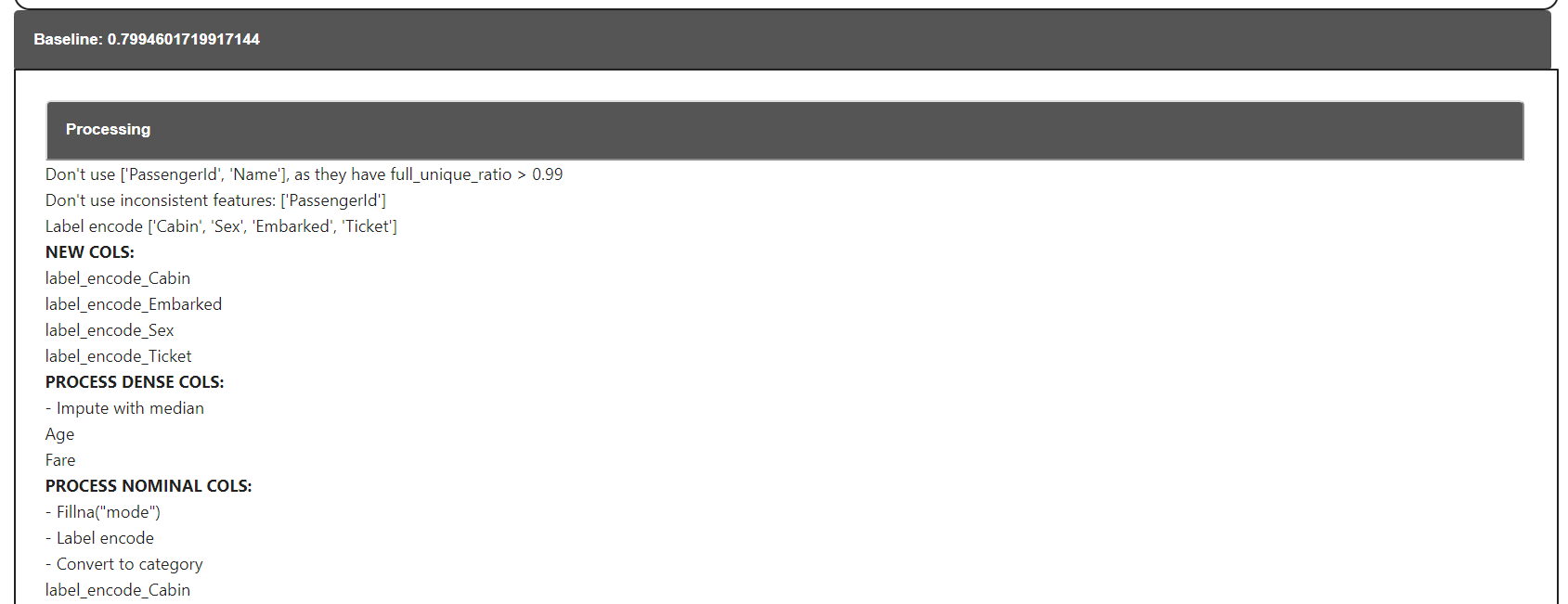

Create submission and save pipeline
create submission:
# Convert test_preds to int from probabilities
# Since this competition requires values to be 0 or 1,
# We have to adjust a decision threshold. While selecting this threshold,
# criteria is to make mean(label) equal to mean(predictions)
# This step is not necessary in most projects
test_preds = (res['test_preds'] > 0.55).astype('int')
# Prepare submission file
to_sub = sub.copy()
to_sub[label_name] = test_preds
to_sub.to_csv('titanic_sub.csv', index = False)
test_preds.mean()
# Baseline LB score: 0.76555save pipeline:
lr_pipeline.save_project()Experiments:
New steps should be tried in a separate notebook. First, load the previously saved pipeline.
lr_pipeline = pipe.Pipeline(project_path = 'lr_pipeline')Then, create a function to create a kaggle submission for this competition. This is not a part of the library.
# Convert to (1,0) from probabilities
def make_submission(res, thresh):
test_preds = (res['test_preds'] > thresh).astype('int')
# Print mean to adjust threshold
print(test_preds.mean())
# Save submission
sub = pd.read_csv(r'data/gender_submission.csv')
to_sub = sub.copy()
to_sub[lr_pipeline.label_name] = test_preds
to_sub.to_csv('titanic_sub.csv', index = False)Then we will try default steps for preprocessing and imputation.
Default steps that will be tried:
For nominals, features with missing values are imputed in 3 different ways. These are: (Baseline model imputes with the most frequent value.)
- Separate category (-9999)
- Impute by dependent (If missing values depend on another feature, this method will be useful.)
Other default steps for nominals is to:
- One-hot encode if specified
- Group values with value_count < limit (default for limit is 10.)
For numeric steps, features with missing values are imputed in 3 different ways. These are:
- Mean impute
- Impute by dependent
- Impute with fixed value (-9999)
Other steps: Binning (if specified), One-hot encoding for binned features (if specified.) One-hot encoding (if specified.)
Standardization
When we were creating a baseline step, we used argument
model = pmodels.train_sklearn_pipelinepmodels.train_sklearn_pipeline standardizes all features if model_type = 'linear'.
Sparse data
Categoricals that were OHEd and numerics that were binned and OHEd are kept in sparse form.
Access current form of data
You can get the dataset from pipeline using,
train, test = mypipeline.load_files()train and test are DataTable instances, which are stored in pickles. DataTable is a class created to keep dataframes and sparse matrices together. When a column from a DataTable is OHEd, it is converted to a sparse matrix and added to the DataTable. Then, features can be accessed in the same way as in pandas.
try nominal steps:
steps.try_default_nominal_steps(lr_pipeline,
ohe = True,
group_outliers = True,
ohe_max_unique = 5000)try numeric steps:
steps.try_default_numeric_steps(lr_pipeline,
ohe = True,
binning = True)Example output for nominals:

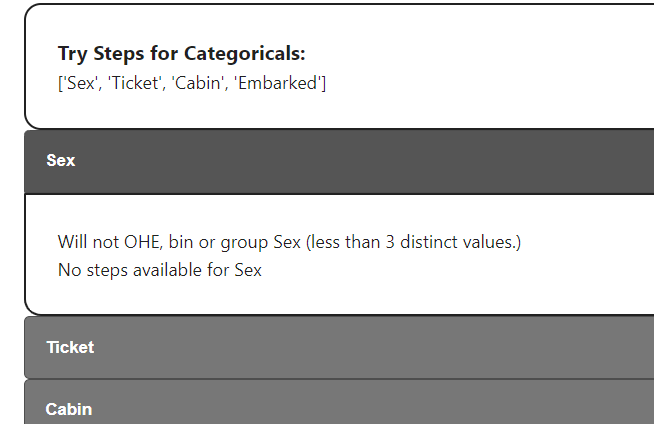

Steps of each step can be also viewed.
Test after default steps
# When model is not specified, it is the baseline model
lr_pipeline.add_model('lr')
res = lr_pipeline.run_model('lr',
hyperparam_search = False,
return_pred = True,
use_final_params = True)make_submission(res, 0.675)Try custom steps
In order to try new steps, write your own function with the following arguments and outputs:
def my_step(feature_properties, train, test, label_name, MYARG1, MYARG2, ...):
# first 4 features are obligatory, but you can add other arguments.
# Arguments other than the first 4 must be provided to add_step function in
# parameter proc_params as a dictionary
# Preprocessing, FE, ... (Mutate train, test)
return cols_not_to_model, train, testanother example:
def my_step(feature_properties, train, test, label_name):
# Add a new column to train, test
train['mycol'] = train['a'] + train['b']
test['mycol'] = test['a'] + test['b']
# Add absolute value of a
for df in [train, test]:
df['abs_a'] = df['a'].abs()
# We don't want 'a' to be used in training. If it will be used in future, don't drop 'a'.
# Instead, add it to cols_not_to_model.
# If all columns will be used, place [ ] in cols_not_to_model.
cols_not_to_model = ['a']
return cols_not_to_model, train, testexample from titanic:
# Extract title from Name
def add_title(feature_properties, train, test, label_name):
# From: https://www.kaggle.com/kpacocha/top-5-titanic-machine-learning-from-disaster
def fe_title(df, col):
title_col = df.Name.str.extract(' ([A-Za-z]+)\.', expand=False)
title_col = np.where((title_col=='Capt') | (title_col=='Countess')
| (title_col=='Don') | (title_col=='Dona')
| (title_col=='Jonkheer') | (title_col=='Lady')
| (title_col=='Sir') | (title_col=='Major')
| (title_col=='Rev') | (title_col=='Col'),
'Other',title_col)
title_col = pd.Series(title_col)
title_col = title_col.replace('Ms','Miss')
title_col = title_col.replace('Mlle','Miss')
title_col = title_col.replace('Mme','Mrs')
return title_col
# utils.utilize is a python decorator that transforms a function from:
# - takes dataframe, column name as input, returns pd.Series
# to:
# - takes multiple dataframes, can return a pd.Series, can add new column to
# dataframes with a new name or replaces the original.
# This behavior is controlled by 'mode' argument.
# mode:
# - 'add': add resulting column to the dataframe with a generated name
# - 'replace': replace original column.
# - 'return' : return pd.Series for each df.
#
# utilize also has join_dfs argument (default=True)
# if join_dfs = True, operation is carried out after concatenating the column
# from dataframes.
# Process name, append result to train and test.
utils.utilize(mode = 'add')(fe_title)([train, test], 'Name')
# This is the name of the added column.
# Names are generated by utilize using this template:
# '{function_name}_{col}'
#
# (This is if col is a single string. It can be a list)
new_name = 'fe_title_Name'
# Label encode new column and replace it.
utils.utilize(mode = 'replace')(prep.label_encode)([train, test], new_name)
# One hot encode new column
train, test = prep.one_hot_encode([train, test], col = new_name, sparse = True)
return [], train, testTry a new step:
res = lr_pipeline.add_step_apply_if_useful(proc = add_title)output: (details can be viewed by clicking on add_title)

create a kaggle submission:
make_submission(res, 0.7335)Try mutually exclusive steps:
Some steps are mutually excusive, which means that you will only apply one of them, even if more than one is useful. For example, different methods of imputations are mutually exclusive.
Code
def add_prefix(feature_properties, train, test, label_name, col_name):
def prefix(df, col):
def get_prefix(x):
x = str(x)
if len(x) == 1:
return x
else:
return x.split(' ')[0][0]
return df[col].apply(lambda x: get_prefix(x))
utils.utilize(mode = 'add')(prefix)([train, test], col_name)
new_name = f'prefix_{col_name}'
utils.utilize(mode = 'replace')(prep.label_encode)([train, test], new_name)
train, test = prep.one_hot_encode([train, test],
col = new_name,
mode = 'replace')
return [], train, test
def add_prefix_group_outliers(
feature_properties, train, test,
label_name, col_name, limit = 10):
@utils.utilize(mode = 'add')
def prefix(df, col):
def get_prefix(x):
x = str(x)
if len(x) == 1:
return x
else:
return x.split(' ')[0][0]
return df[col].apply(lambda x: get_prefix(x))
prefix([train, test], col_name)
new_name = f'prefix_{col_name}'
utils.utilize(mode = 'replace')(prep.label_encode)([train, test], new_name)
prep.group_outliers_replace([train, test], new_name, limit = limit)
train, test = prep.one_hot_encode([train, test],
col = new_name,
mode = 'add')
# Don't drop the original column, but don't use it in training
return [col_name], train, test
lr_pipeline.add_step(proc = add_prefix,
group = 'prefix_ticket',
proc_params= {'col_name': 'Ticket'})
lr_pipeline.add_step(proc = add_prefix_group_outliers,
group = 'prefix_ticket',
proc_params= {'col_name': 'Ticket'})
res = lr_pipeline.group_apply_useful('prefix_ticket')output:
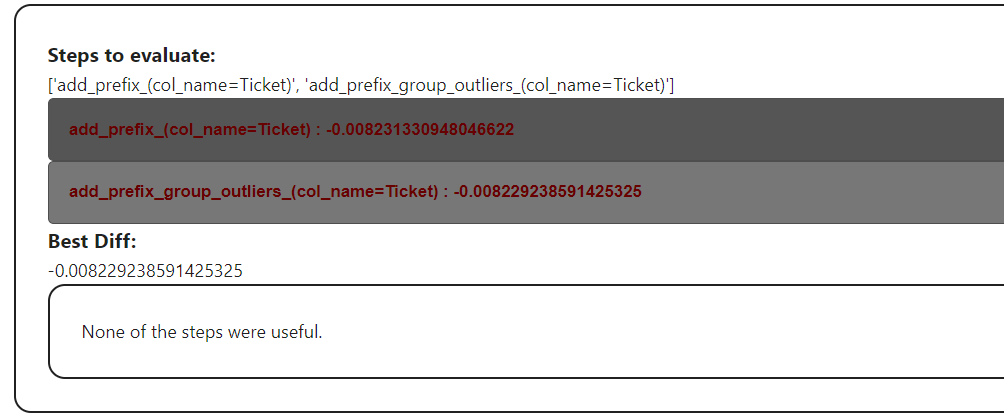
No need to generate a submission for this one, as nothing was changed in the data.
Train other models (or train from scratch using bayesian search)
Train baseline model. (using hparams determined in line search) (Training baseline is necessary only if you will stack/blend)
train baseline:
# When model is not specified, it is the baseline model
lr_pipeline.add_model('lr')
res = lr_pipeline.run_model('lr',
hyperparam_search = False,
return_pred = True,
use_final_params = True)output:

train svm: fixed_hparams and search_hparams can be used in other projects as they are. (I will add them to the library soon.)
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
fixed_hparams = dict(model = SVC,
probability = True,
random_state = 42,
score = accuracy_score,
max_iter = 2000,
folds=[KFold(n_splits= 5, shuffle = True, random_state = 42),
KFold(n_splits= 5, shuffle = True, random_state = 13),
KFold(n_splits= 5, shuffle = True, random_state = 100)
])
search_hparams = dict(C = hp.loguniform('C', -3, 7),
gamma = hp.loguniform('gamma', -3, 3),
class_weight = hp.choice('class_weight', ['balanced', None]),
kernel = hp.choice('kernel', ['linear', 'rbf', 'poly'])
)
lr_pipeline.add_model('svc',
model = pmodels.train_sklearn_pipeline,
fixed_hparams = fixed_hparams,
search_hparams = search_hparams)
res = lr_pipeline.run_model('svc', return_pred = True, hyperparam_search = True)create submission: You should test each model before stacking/blending.
make_submission(res, 0.675)train kneighbors:
from sklearn.neighbors import KNeighborsClassifier
fixed_hparams = dict(model = KNeighborsClassifier,
folds = lr_pipeline.baseline_step['model_params']['folds'],
score = accuracy_score)
search_hparams = dict(n_neighbors = hp.choice('n_neighbors', np.arange(4,25)),
leaf_size = hp.choice('leaf_size', np.arange(15,50)))
lr_pipeline.add_model('kn',
model = pmodels.train_sklearn_pipeline,
fixed_hparams = fixed_hparams,
search_hparams = search_hparams)
res = lr_pipeline.run_model('kn', hyperparam_search = True)output:

create submission:
make_submission(res, 0.675)Blending
(Stacking will be also available.)
blend predictions in a directory:
res = {}
res['test_preds'] = putils.blend_from_csv(directory = lr_pipeline.test_preds_path)create submission:
make_submission(res, 0.7)save project:
lr_pipeline.save_project()Note:
Ideally, you should place each new experiment/step in a new notebook and save project after each useful step. In Titanic example, baseline is in its own notebook, but following steps are in a second one, to keep the example simpler.
