![]()




![]()
Project's Website • Key Features • How To Use • Benchmark Datasets • Community Support • Contributing • Mission • License
Take a look at our official page for user documentation and examples: langtest.org
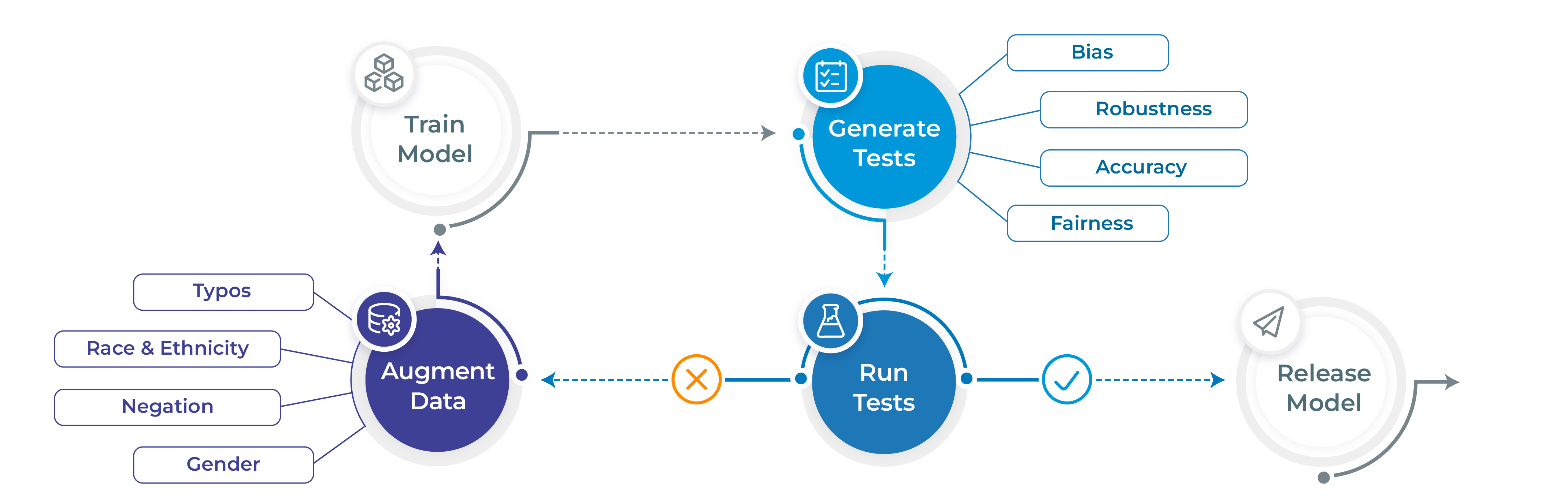
- Generate and execute more than 60 distinct types of tests only with 1 line of code
- Test all aspects of model quality: robustness, bias, representation, fairness and accuracy.
- Automatically augment training data based on test results (for select models)
- Support for popular NLP frameworks for NER, Translation and Text-Classifcation: Spark NLP, Hugging Face & Transformers.
- Support for testing LLMS ( OpenAI, Cohere, AI21, Hugging Face Inference API and Azure-OpenAI LLMs) for question answering, toxicity, clinical-tests, legal-support, factuality, sycophancy, summarization and other popular tests.
LangTest comes with different datasets to test your models, covering a wide range of use cases and evaluation scenarios. You can explore all the benchmark datasets available here, each meticulously curated to challenge and enhance your language models. Whether you're focused on Question-Answering, text summarization etc, LangTest ensures you have the right data to push your models to their limits and achieve peak performance in diverse linguistic tasks.
# Install langtest
!pip install langtest[transformers]
# Import and create a Harness object
from langtest import Harness
h = Harness(task='ner', model={"model":'dslim/bert-base-NER', "hub":'huggingface'})
# Generate test cases, run them and view a report
h.generate().run().report()Note For more extended examples of usage and documentation, head over to langtest.org
You can check out the following LangTest articles:
| Blog | Description |
|---|---|
| Automatically Testing for Demographic Bias in Clinical Treatment Plans Generated by Large Language Models | Helps in understanding and testing demographic bias in clinical treatment plans generated by LLM. |
| LangTest: Unveiling & Fixing Biases with End-to-End NLP Pipelines | The end-to-end language pipeline in LangTest empowers NLP practitioners to tackle biases in language models with a comprehensive, data-driven, and iterative approach. |
| Beyond Accuracy: Robustness Testing of Named Entity Recognition Models with LangTest | While accuracy is undoubtedly crucial, robustness testing takes natural language processing (NLP) models evaluation to the next level by ensuring that models can perform reliably and consistently across a wide array of real-world conditions. |
| Elevate Your NLP Models with Automated Data Augmentation for Enhanced Performance | In this article, we discuss how automated data augmentation may supercharge your NLP models and improve their performance and how we do that using LangTest. |
| Mitigating Gender-Occupational Stereotypes in AI: Evaluating Models with the Wino Bias Test through Langtest Library | In this article, we discuss how we can test the "Wino Bias” using LangTest. It specifically refers to testing biases arising from gender-occupational stereotypes. |
| Automating Responsible AI: Integrating Hugging Face and LangTest for More Robust Models | In this article, we have explored the integration between Hugging Face, your go-to source for state-of-the-art NLP models and datasets, and LangTest, your NLP pipeline’s secret weapon for testing and optimization. |
| Detecting and Evaluating Sycophancy Bias: An Analysis of LLM and AI Solutions | In this blog post, we discuss the pervasive issue of sycophantic AI behavior and the challenges it presents in the world of artificial intelligence. We explore how language models sometimes prioritize agreement over authenticity, hindering meaningful and unbiased conversations. Furthermore, we unveil a potential game-changing solution to this problem, synthetic data, which promises to revolutionize the way AI companions engage in discussions, making them more reliable and accurate across various real-world conditions. |
| Unmasking Language Model Sensitivity in Negation and Toxicity Evaluations | In this blog post, we delve into Language Model Sensitivity, examining how models handle negations and toxicity in language. Through these tests, we gain insights into the models' adaptability and responsiveness, emphasizing the continuous need for improvement in NLP models. |
| Unveiling Bias in Language Models: Gender, Race, Disability, and Socioeconomic Perspectives | In this blog post, we explore bias in Language Models, focusing on gender, race, disability, and socioeconomic factors. We assess this bias using the CrowS-Pairs dataset, designed to measure stereotypical biases. To address these biases, we discuss the importance of tools like LangTest in promoting fairness in NLP systems. |
| Unmasking the Biases Within AI: How Gender, Ethnicity, Religion, and Economics Shape NLP and Beyond | In this blog post, we tackle AI bias on how Gender, Ethnicity, Religion, and Economics Shape NLP systems. We discussed strategies for reducing bias and promoting fairness in AI systems. |
| Evaluating Large Language Models on Gender-Occupational Stereotypes Using the Wino Bias Test | In this blog post, we dive into testing the WinoBias dataset on LLMs, examining language models’ handling of gender and occupational roles, evaluation metrics, and the wider implications. Let’s explore the evaluation of language models with LangTest on the WinoBias dataset and confront the challenges of addressing bias in AI. |
| Streamlining ML Workflows: Integrating MLFlow Tracking with LangTest for Enhanced Model Evaluations | In this blog post, we dive into the growing need for transparent, systematic, and comprehensive tracking of models. Enter MLFlow and LangTest: two tools that, when combined, create a revolutionary approach to ML development. |
| Testing the Question Answering Capabilities of Large Language Models | In this blog post, we dive into enhancing the QA evaluation capabilities using LangTest library. Explore about different evaluation methods that LangTest offers to address the complexities of evaluating Question Answering (QA) tasks. |
| Evaluating Stereotype Bias with LangTest | In this blog post, we are focusing on using the StereoSet dataset to assess bias related to gender, profession, and race. |
| Testing the Robustness of LSTM-Based Sentiment Analysis Models | Explore the robustness of custom models with LangTest Insights. |
| LangTest Insights: A Deep Dive into LLM Robustness on OpenBookQA | Explore the robustness of Language Models (LLMs) on the OpenBookQA dataset with LangTest Insights. |
| LangTest: A Secret Weapon for Improving the Robustness of Your Transformers Language Models | Explore the robustness of Transformers Language Models with LangTest Insights. |
Note To check all blogs, head over to Blogs
-
Slack For live discussion with the LangTest community, join the
#langtestchannel - GitHub For bug reports, feature requests, and contributions
- Discussions To engage with other community members, share ideas, and show off how you use LangTest!
While there is a lot of talk about the need to train AI models that are safe, robust, and fair - few tools have been made available to data scientists to meet these goals. As a result, the front line of NLP models in production systems reflects a sorry state of affairs.
We propose here an early stage open-source community project that aims to fill this gap, and would love for you to join us on this mission. We aim to build on the foundation laid by previous research such as Ribeiro et al. (2020), Song et al. (2020), Parrish et al. (2021), van Aken et al. (2021) and many others.
John Snow Labs has a full development team allocated to the project and is committed to improving the library for years, as we do with other open-source libraries. Expect frequent releases with new test types, tasks, languages, and platforms to be added regularly. We look forward to working together to make safe, reliable, and responsible NLP an everyday reality.
Note For usage and documentation, head over to langtest.org
We welcome all sorts of contributions:
A detailed overview of contributing can be found in the contributing guide.
If you are looking to start working with the LangTest codebase, navigate to the GitHub "issues" tab and start looking through interesting issues. There are a number of issues listed under where you could start out. Or maybe through using LangTest you have an idea of your own or are looking for something in the documentation and thinking ‘This can be improved’...you can do something about it!
Feel free to ask questions on the Q&A discussions.
As contributors and maintainers to this project, you are expected to abide by LangTest's code of conduct. More information can be found at: Contributor Code of Conduct
We have published a paper that you can cite for the LangTest library:
@article{nazir2024langtest,
title={LangTest: A comprehensive evaluation library for custom LLM and NLP models},
author={Arshaan Nazir, Thadaka Kalyan Chakravarthy, David Amore Cecchini, Rakshit Khajuria, Prikshit Sharma, Ali Tarik Mirik, Veysel Kocaman and David Talby},
journal={Software Impacts},
pages={100619},
year={2024},
publisher={Elsevier}
}We would like to acknowledge all contributors of this open-source community project.
LangTest is released under the Apache License 2.0, which guarantees commercial use, modification, distribution, patent use, private use and sets limitations on trademark use, liability and warranty.













