pareto.py
Nondominated sorting for multi-objective problems
by matthewjwoodruff and jdherman
pareto.py implements an epsilon-nondominated sort in pure Python. It sorts one or more files of solutions into the Pareto-efficient (or "nondominated") set. Solutions can contain columns other than objectives, which will be carried through, unsorted, to the output. By default, output rows are reproduced verbatim from input. pareto.py supports both minimization and maximization, although it assumes minimization.
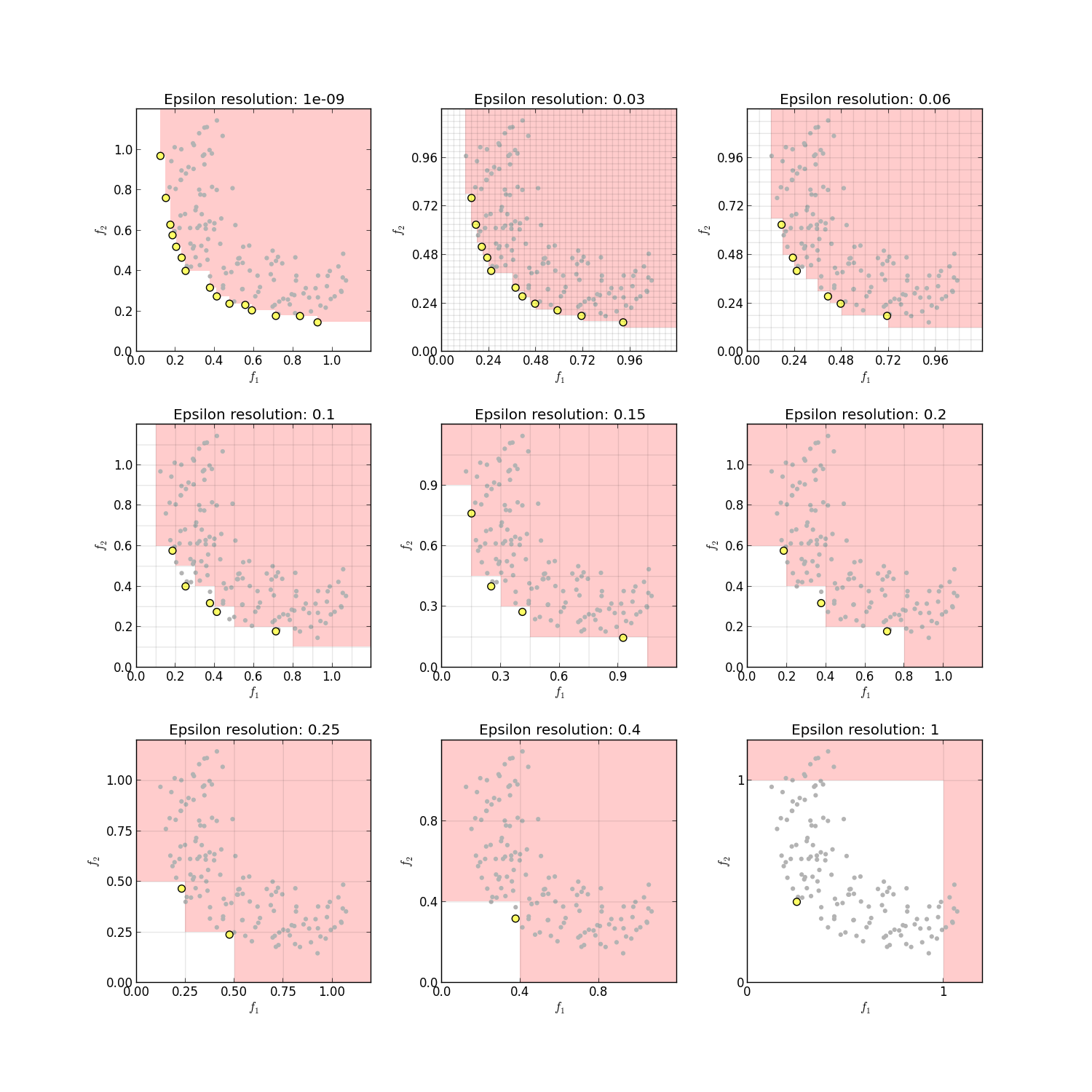
This sort assumes a desired output resolution (epsilons). If a strict nondominated sort is required, it can be approximated by setting epsilons arbitrarily small (within reason -- floating-point division is involved here.) The default epsilon resolution of 1e-9 will effectively result in a strict nondominated sort in many cases.

Data prior to sorting. Objectives f1 and f2 are both to be minimized.

Data after epsilon-nondominated sort. Red epsilon-boxes and all of the solutions in them are dominated. Marked solutions are epsilon-nondominated.
This picture shows the same data sorted at a variety of epsilon resolutions. (Note that there is no requirement that epsilons be the same for each objective. Epsilons for f1 and f2 are set equal for illustration only.)
Usage
Example usage for a group of input files beginning with my_file_:
python pareto.py \
my_file_* \
-o 3-5 \
-e 0.01 0.05 0.1 \
-m 3 \
--output my_pareto_set.txt \
--delimiter=' ' \
--print-only-objectives \
--header=1 \
--blank \
--comment="#" \
--contribution \
--line-number
inputs: Required. List of input files to sort, separated by spaces. Input files are assumed to contain floating-point values separated bydelimiter. Input files must all contain the same number of columns.-may be specified as an input, indicating standard input. This allowspareto.pyto be part of a pipeline.--output: Optional. Filename to output your Pareto set.-o, --objectives: Optional. A list of columns of the input files to sort (zero-indexed), separated by spaces. If not given, all columns of the input files will be sorted. Ranges and individual column numbers may be mixed, e.g.-o 0 3-7 12-e, --epsilons: Optional. A list of epsilon (precision) values corresponding to each objective. If not given, all objectives will use a precision of1e-9.-m, --maximize: Optional. A list of objective columns to maximize. By default,pareto.pyminimizes all objectives.-M, --maximize-all: Optional. Maximize all objectives. Overrides-m.-
-d, --delimiter: Optional. Input file delimiter. Common choices:- Space-delimited (default):
--delimiter=' ' - Comma-delimited:
--delimiter=',' - Tab:
--tabs(see below)
- Space-delimited (default):
--tabs: Use tabs as delimiter. Provided for convenience because tabs can be difficult to escape properly at the command line.--print-only-objectives: Optional. Include this flag to print only the objective values in the Pareto set. If this flag is not included, all columns of the input will be printed to the output, even if they were not sorted.--header: Optional. Number of rows to skip at the top of each input. If the header is prefixed with a comment character (see--comment) this is unnecessary.-c, --comment: Optional. Character to look for at the beginning of a row indicating that the row contains a comment and should be ignored. Commented rows are not preserved in output. More than one character may be specified. For example,-c "#" "//"will cause lines starting with either#or//to be skipped.--blank: Optional. Skip blank rows instead of erroring out.--contribution: Optional. Append filename of origin to each solution in the output.--line-number: Optional. Report line number in file of origin when appending contribution.--reverse-column-indices: Optional. Count column indices from the end of the row rather than from the beginning. This affects the behavior of-o,-e, and-m.-oand-mwill count from the end of the row, which reverses the order of the objectives from the point of view of-e. So if you specify-o 0-2 --reverse-column-indices -e 0.1 0.2 0.2 -m 0, the last column of each row gets maximized with epsilon 0.1, while the two columns before it get minimized with epsilon 0.2. If you want to specify epsilons in forward order, switch the direction of the index range:-o 2-0 --reverse-column-indices -e 0.2 0.2 0.1 -m 0has the same effect.
What is this?
For more information, please consult the following references:
http://www.iitk.ac.in/kangal/index.shtml: Kanpur Genetic Algorithms Laboratory Homepage
http://waterprogramming.wordpress.com: Waterprogramming Research Blog
Deb, K., M. Mohan, and S. Mishra. 2005 "Evaluating the epsilon-domination based multiobjective evolutionary algorithm for a quick computation of Pareto-optimal solutions" Evolutionary Computation Journal 13 (4): 501-525.
Deb, K., A. Pratap, S. Agarwal, and T. Meyarivan. 2002. "A fast and elitist multiobjective genetic algorithm: NSGA-II." IEEE Transactions on Evolutionary Computation 6 (2): 182-197.
Srinivas, N., and K. Deb. 1994. "Multiobjective optimization using nondominated sorting in genetic algorithms." Evolutionary Computation 2 (2): 221-248.
But what is it for?
Among other things, pareto.py can serve the following purposes:
- Post-process the output of multiple optimization runs. Since multiple-objective evolutionary algorithms (MOEAs) are search heuristics using random numbers, they may be run more than once and produce different output each time. Therefore the estabilshed best practice for MOEA users is to sort together the output of as many optimization runs as possible to get a good approximation of the true Pareto-efficient set.
- Combine the output of more than one MOEA, for research studies comparing the performance of different MOEAs. This is useful when computing metrics of optimization performance such as hypervolume and the epsilon-indicator.
- Find the Pareto-efficient solutions within a set of unsorted data.
- Prepare reference data for validating other implementations of epsilon-nondominated sorting routines.
- Understand how epsilon-nondominated sorting works by reading and modifying the source code.
Alternatives
The ReferenceSetMerger from moeaframework (http://www.moeaframework.org) tends to be faster then pareto.py when the reference set is large, i.e. when a lot of comparisons must be made for each solution. pareto.py seems to have a speed advantage in situations where reading the input file is the limiting factor. ReferenceSetMerger tends to use a great deal more RAM.
YMMV, TANSTAAFL.
Dependencies
- Python standard library (
sys,math, andargparse) - Python 2.7 or later, Python 3.2 or later (for
argparse)
Note for Pandas users
Pandas is an excellent library for Python data analysis. Doing a nondominated
sort on a Pandas Data Frame requires itertuples(False), because pareto.py expects
to be able to iterate over rows. The False argument excludes the index. It can
be included if desired, but the objective columns should be adjusted accordingly.
import pandas
import pareto
table = pandas.read_table("datafile.txt")
nondominated = pareto.eps_sort([table.itertuples(False)], [3, 4, 5], [1, 0.1, 3])
Note for PyPy users
Congratulations! You're using a blazing fast Python interpreter. pareto.py works great with PyPy. A recent comparison on a 692M file with 10 objectives, 27 other columns, and a reference set of 507 solutions, ran in 23.5s using pypy (version 2.1.0), versus 8m29s with CPython 2.7.5. (Disclaimer: many factors affect performance. This is an anecdotal result.)
Note for Python3 users
pareto.py works with Python3.2 and up. However, informal performance comparisons show a speed regression of about 30% for CPython 3.3.2 versus 2.7.5, possibly because we're being naive about string handling.
License
Copyright (C) 2013 Matt Woodruff and Jon Herman. Licensed under the GNU Lesser General Public License.
pareto.py is free software: you can redistribute it and/or modify it under the terms of the GNU Lesser General Public License as published by the Free Software Foundation, either version 3 of the License, or (at your option) any later version.
pareto.py is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public License along with the pareto.py. If not, see http://www.gnu.org/licenses/.


{kind=link}