Pylearning: python machine learning library


Pylearning is a high-level machine learning package designed to easily prototype and implement data analysis programs.
The library includes the following algorithms:
- Regression:
- Decision tree regressor
- Random forest regressor
- Nearest neighbours regressor
- Classification:
- Decision tree classifier
- Random forest classifier
- Nearest neighbours classifier
- Clustering:
- K-means
- DBSCAN (density-based clustering)
The two random forests algorithms use multithreading to train the trees in a parallelized fashion. This package is compatible with Python3+.
Basic usage
All the algorithms available use the same simple interface described in the examples below.
# Basic regression example using a random forest
from pylearning.ensembles import RandomForestRegressor
# Load the training dataset
features, targets = ...
rf = RandomForestRegressor(nb_trees=10, nb_samples=100, max_depth=20)
rf.fit(features, targets)
# Load a testing sample
test_feature, test_target = ...
value_predicted = rf.predict(test_feature, test_target)# Clustering example using DBSCAN algorithm
import matplotlib.pyplot as plt
from pylearning.clustering import DBSCAN
from sklearn.datasets import make_circles
# Load a dataset composed of two circles
data = make_circles(n_samples=1000, noise=0.05, factor=0.3)[0]
cl = DBSCAN(epsilon=0.2)
cl.fit(data)
labels_data = {i: ([],[]) for i in range(-1, 2)}
for ex, label in zip(data, cl.labels):
labels_data[label][0].append(ex[0])
labels_data[label][1].append(ex[1])
colors = ['g','b']
for label, values in labels_data.items():
if label == -1:
plt.scatter(values[0], values[1], color='black')
else:
plt.scatter(values[0], values[1], color=colors[label], s=50)
plt.show()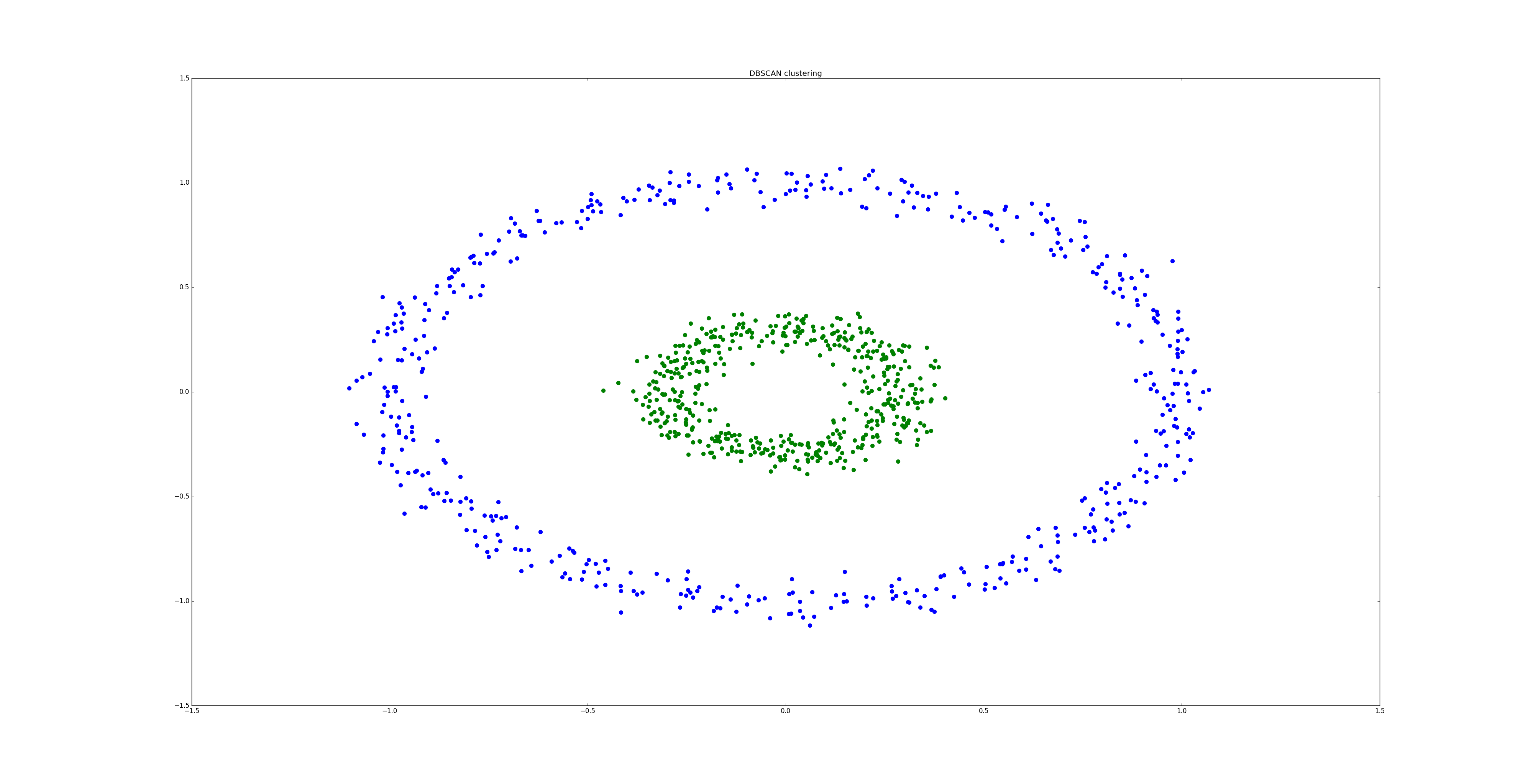
A complete documentation of the API is available here.
Installation
Pylearning requires to have numpy installed. It can be installed simply using Pypy:
# for the stable version
pip3 install pylearning
# for the latest version
pip3 install git+https://github.com/amstuta/pylearning.gitFurther improvements
The core functionalities of the different algorithms are implemented in this project, however there are many possible improvements:
- gini criterion for splitting nodes (Decision trees)
- pruning (Decision trees)
- ability to split a node into an arbitrary number of child nodes (Decision trees)
- optimizations to reduce time and memory consumption
- better compatibility with pandas DataFrame
- addition of new algorithms (density-based clustering, SVM, neural networks, ...)
If you wish, you're welcome to participate in the project or to make suggestions ! To do so, you can simply open an issue or fork the project and then create a pull request.

