Text-to-Text Transformer
본 repository에서는 Google의 T5(T5: Text-To-Text Transfer Transformer)의 text-to-text 형태로 한국어 QA Task를 위한 Transformer 모델입니다. 전체 모델의 아키텍처는 기본 Transformer 모델을 사용했습니다.
pip install transformer-korean
- 2019.12.25, version 0.0.3 : load_data_txt, load_data_csv 오류 수정
- 2019.12.23, version 0.0.1 : 최초 릴리즈
0. Pre-training Model
- Text-to-Text Transformer-Base, Korean Model: 12-layer, 768-hidden, 12-heads(비공개)
- Text-to-Text Transformer-Small, Korean Model: 6-layer, 512-hidden, 8-heads(비공개)
Base This is our baseline model, whose hyperparameters are described in Section 3.1.1. It has roughly 220million parameters. Small. We consider a smaller model, which scales the baseline down by using dmodel= 512, dff= 2,048, 8-headed attention, and only 6layers each in the encoder and decoder. This varianthas about 60million parameters.
1. Pre-training
1.1 Unsupervised objective
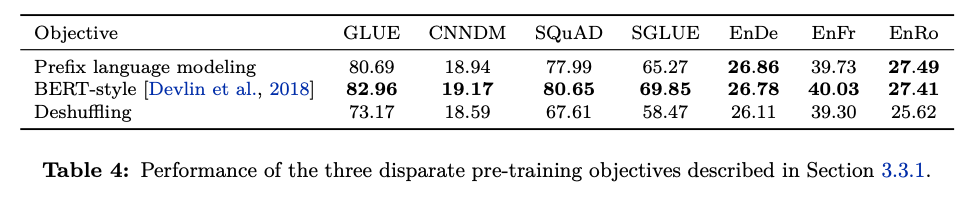
T5 논문에서 가장 성능이 잘 나온다고 서술된 BERT Style Objective로 문장을 구성하여, Pre-training 하도록 구성했습니다. BERT와 동일하게 입력 문장의 15%를 Random 하게 마스킹 처리했습니다. 마스킹 대상의 80%는 토큰으로 대체하며, 10%는 사전 내 임의의 토큰으로 나머지 10%는 원래의 단어를 그대로 사용했습니다.

1.2 문장 예시
Input 문장 : 1900년, <MASK> <MASK> 푸치니의 오페라 토스카로 '다양하게' 각색되었다. (BERT Style)
Target 문장 : 1900년, 사르두의 연극은 푸치니의 오페라 토스카로 새롭게 각색되었다. (original text)
1.3 Unlabeld dataset
학습 데이터는 한국어 위키데이터(2019.01 dump file 기준, 약 350만 문장) 을 사용하여 학습을 진행했으며, 학습 문장 구성은 아래와 같습니다.
라 토스카(La Tosca)는 1887년에 프랑스 극작가 사르두가 배우 사라 베르나르를 위해 만든 작품이다.
1887년 파리에서 처음 상연되었다.
1990년 베르나르를 주인공으로 미국 뉴욕에서 재상연되었다.
1800년 6월 중순의 이탈리아 로마를 배경으로 하며, 당시의 시대적 상황 하에서 이야기가 전개된다.
1900년, 사르두의 연극은 푸치니의 오페라 토스카로 새롭게 각색되었다.
베르디는 사드루의 각본에서 "갑작스런 종결" 부분을 수정할 것을 권하지만, 사르루는 이를 거절한다.
후에, 푸치니 또한 사르두의 각본에서 "갑작스런 종결부분"을 수정할 것을 제안하지만 끝내 사르두를 설득하지 못했다.
1.4 학습 예
from transformer_korean.run_training import Trainer
from transformer_korean.transformer import Transformer
from transformer_korean.preprocess import DataProcessor
from transformer_korean.custom_scheduler import CustomSchedule
import tensorflow as tf
path = "ko-wiki_20190621.txt"
# Data Processing
print('Loading Pre-training data')
data_preprocess = DataProcessor(txt_path=path,
batch_size=64,
pre_train=True,
max_length=128)
train = data_preprocess.load_data_txt()
print('Loading Vocab File')
vocab = data_preprocess.load_vocab_file(vocab_filename="vocab")
print('Create train dataset')
train_dataset = data_preprocess.preprocess(train)
EPOCHS = 100
num_layers = 6
d_model = 128
dff = 512
num_heads = 8
vocab_size = vocab.vocab_size
dropout_rate = 0.1
encoder_activation = 'gelu'
decoder_activation = 'relu'
# Custom Scheduler
learning_rate = CustomSchedule(d_model, warmup_steps=4000)
optimizer = tf.keras.optimizers.Adam(learning_rate, beta_1=0.9, beta_2=0.98, epsilon=1e-9)
# Transformer
transformer = Transformer(d_model=d_model,
num_heads=num_heads,
num_layers=num_layers,
vocab_size=vocab_size,
dff=dff,
enc_activation=encoder_activation,
dec_activation=decoder_activation,
rate=dropout_rate)
# Trainer
trainer = Trainer(train_dataset=train_dataset,
learning_rate=learning_rate,
optimizer=optimizer,
transformer=transformer,
epochs=EPOCHS,
checkpoint_path='./checkpoints/',
load_checkpoints=False,
save_checkpoints_epochs=10)
trainer.train()2.Fine-Tuning(QA Task)
2.1 Labeld dataset
QA Task를 위해 한국어 QA Dataset인 KorQuAD 1.1을 사용하여 Fine-Tuning 하도록 구성했습니다. 데이터 구성은 아래와 같습니다. input은 question, target은 answer가 되도록 했습니다.
Q
바그너는 괴테의 파우스트를 읽고 무엇을 쓰고자 했는가?
바그너는 교향곡 작곡을 어디까지 쓴 뒤에 중단했는가?
바그너가 파우스트 서곡을 쓸 때 어떤 곡의 영향을 받았는가?
1839년 바그너가 교향곡의 소재로 쓰려고 했던 책은?
파우스트 서곡의 라단조 조성이 영향을 받은 베토벤의 곡은?
A
교향곡
1악장
베토벤의 교향곡 9번
파우스트
합창교향곡
2.2 학습 예
from transformer_korean.run_training import Trainer
from transformer_korean.transformer import Transformer
from transformer_korean.preprocess import DataProcessor
from transformer_korean.custom_scheduler import CustomSchedule
import tensorflow as tf
question = "KorQuAD_train_q.csv"
answer = "KorQuAD_train_a.csv"
# Data Processing
print('Loading fine-tuning data')
data_preprocess = DataProcessor(csv_path=[question, answer],
batch_size=64,
pre_train=False,
max_length= 128)
train = data_preprocess.load_data_csv()
print('Loading Vocab File')
vocab = data_preprocess.load_vocab_file(vocab_filename="vocab")
print('Create train dataset')
train_dataset = data_preprocess.preprocess(train)
EPOCHS = 100
num_layers = 6
d_model = 128
dff = 512
num_heads = 8
vocab_size = vocab.vocab_size
dropout_rate = 0.1
encoder_activation = 'gelu'
decoder_activation = 'relu'
# Custom Scheduler
learning_rate = CustomSchedule(d_model, warmup_steps=4000)
optimizer = tf.keras.optimizers.Adam(learning_rate, beta_1=0.9, beta_2=0.98, epsilon=1e-9)
# Transformer
transformer = Transformer(d_model=d_model,
num_heads=num_heads,
num_layers=num_layers,
vocab_size=vocab_size,
dff=dff,
enc_activation = encoder_activation,
dec_activation = decoder_activation,
rate=dropout_rate)
# Trainer
trainer = Trainer(train_dataset=train_dataset,
learning_rate=learning_rate,
optimizer=optimizer,
transformer=transformer,
epochs=EPOCHS,
checkpoint_path='./checkpoints/',
load_checkpoints=True,
save_checkpoints_epochs=10)
trainer.train()3. Activation Function
기본 relu activation function 외에 4개의 activation function 추가하였으며, Encoder와 Decoder 블럭에 서로 다른 activation function이 사용 가능하도록 했습니다
- gelu
def gelu(x):
cdf = 0.5 * (1.0 + tf.tanh((np.sqrt(2 / np.pi) * (x + 0.044715 * tf.pow(x, 3)))))
return x * cdf- swish
def swish(x):
return x * tf.nn.sigmoid(x)- swish_beta
def swish_beta(x):
beta=tf.Variable(initial_value=1.0,trainable=True, name='swish_beta')
return x * tf.nn.sigmoid(beta * x) #trainable parameter betadef mish(x):
return x * tf.math.tanh(tf.math.softplus(x))4. Requirement
Python == 3.x
tensorflow >=2.0
tensorflow-datasets >= 1.3.2
pandas >= 0.24.2
numpy >= 1.16.3
six>=1.12.0
5. To-Do
- TPU, Multi-GPU 지원 예정
- Dropout 수정 예정
- Predict 모듈 추가 예정
