
Utter More
To customize Amazon's Alexa, you make what is called a skill. To do something in the skill, you make an intent. To run the intent, you make an utterance. When that utterance is uttered, the intent is run. Since language is complex, there may be many different ways to say the same thing and you may want Alexa to pick up on all of those ways. Furthermore, you may have many variables for the utterances (called intent slots). Being verbose enough to cover every case can be tedious, so this takes care of that.
Installing Package
Just do the classic:
pip install utter-more
Or if you're adventurous and use Conda:
conda install -c crumpstrr33 utter-more
Creating Utterances
Below are some examples to show its functionality.
Formatting
You can use the following in your templates:
- OR statement
(a|b|c|...)- Used if you want to allow multiple interchangeable words. For example, ifphoto,pictureandpaintingare interchangeable in your utterances, then write(photo|picture|painting)in the place where it would be. The number of words to OR is arbitrary and single curly keywords like{intent_slot}can be used in this. - Conditional OR statement
(a*tag1|b) (c^tag1|d)- Used if you want the appearance of a phrase in an OR statement to be dependent on another phrase. Here,ais the master andcis the follower; utterances withcwill only appear if it also containsa. Another functionality of this is as follows. If you have(It*s|They*p) (is^s|are^p) (close^s|far^p),isandclosewill only show ifItalso shows and, conversely,areandfarwill only show ifTheyshows. This is how you can do a conditional AND with this function. - Optional Intent Slot
{{slot}}- Used if the existence of an intent slot in your utterance is optional. For example, if you have an optional adverb you may writeI {adverb} love itor justI love it. Instead you can writeI {{adverb}} love itto capture both.
Running the Code
Now with the formatting down, lets create some templates for the utterances. Something like:
"What (is*s|are*p) (that^s|those^p) {{descriptor}} (photo|picture)(^s|s^p) (of|from)"
and
"Download the (photo|picture) {{to_file_path}}"
To do this, we run the following:
from pprint import pprint
from utter_more import UtterMore
um = UtterMore("What (is*s|are*p) (that^s|those^p) {{descriptor}} (photo|picture)(^s|s^p) (of|from)",
"Download the (photo|picture) {{to_file_path}}")
um.iter_build_utterances()
pprint(um.utterances)And this will display:
[['What is that {descriptor} photo of',
'What is that {descriptor} photo from',
'What is that {descriptor} picture of',
'What is that {descriptor} picture from',
'What is that photo of',
'What is that photo from',
'What is that picture of',
'What is that picture from',
'What are those {descriptor} photos of',
'What are those {descriptor} photos from',
'What are those {descriptor} pictures of',
'What are those {descriptor} pictures from',
'What are those photos of',
'What are those photos from',
'What are those pictures of',
'What are those pictures from'],
['Download the photo {to_file_path}',
'Download the photo',
'Download the picture {to_file_path}',
'Download the picture']]Here we can easily follow the grammatical rules of plurality. If we want to save the utterances so that we can upload them to our Alexa skill, we simply do:
um.save_for_alexa(PATH_TO_DIRECTORY, FILE_NAME)Here we will find the CSV file properly formatted for uploading.
Uploading the Utterances
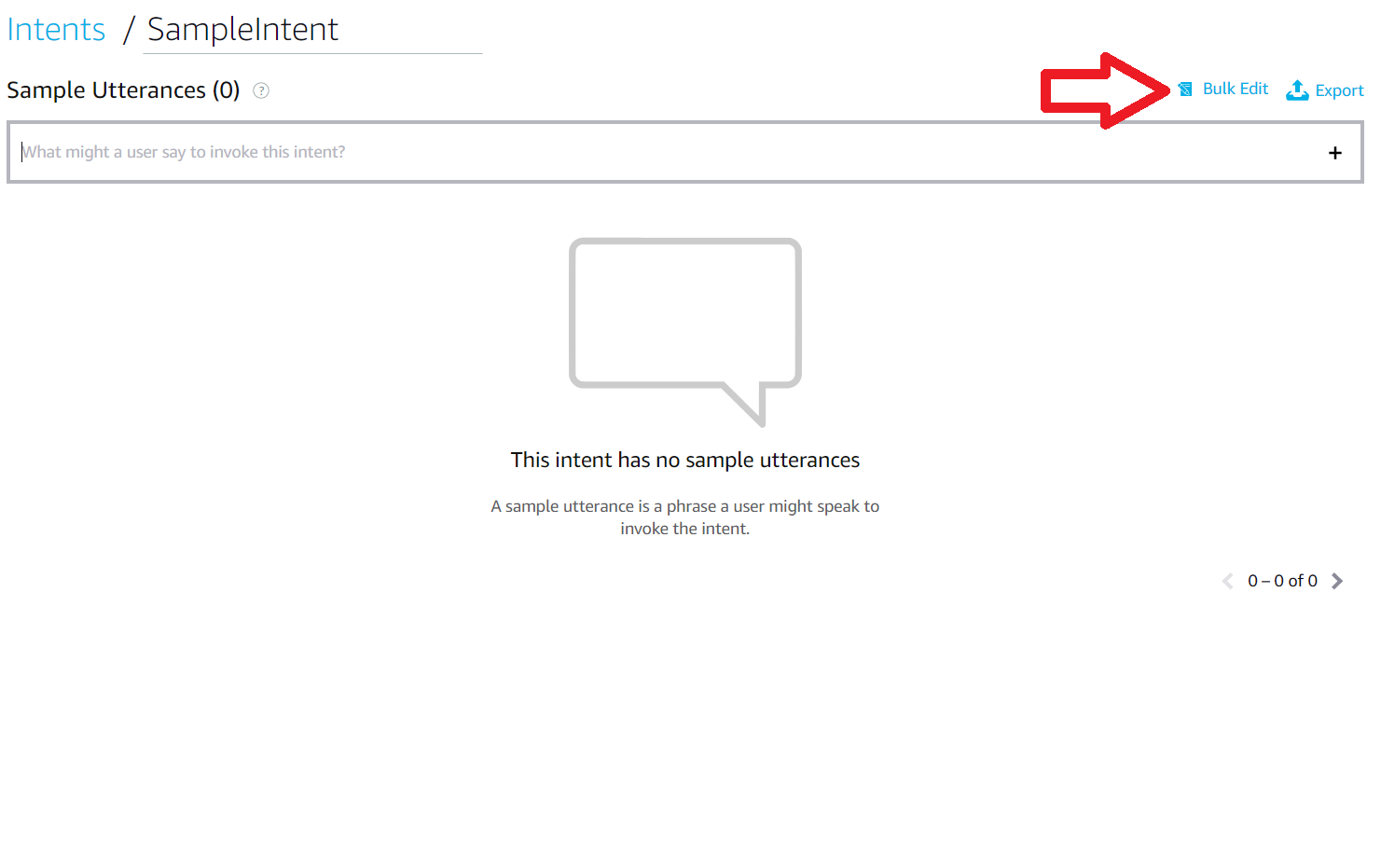
- After going to the tab for the intended intent, click on "Bulk Edit" in the top right corner of the page.
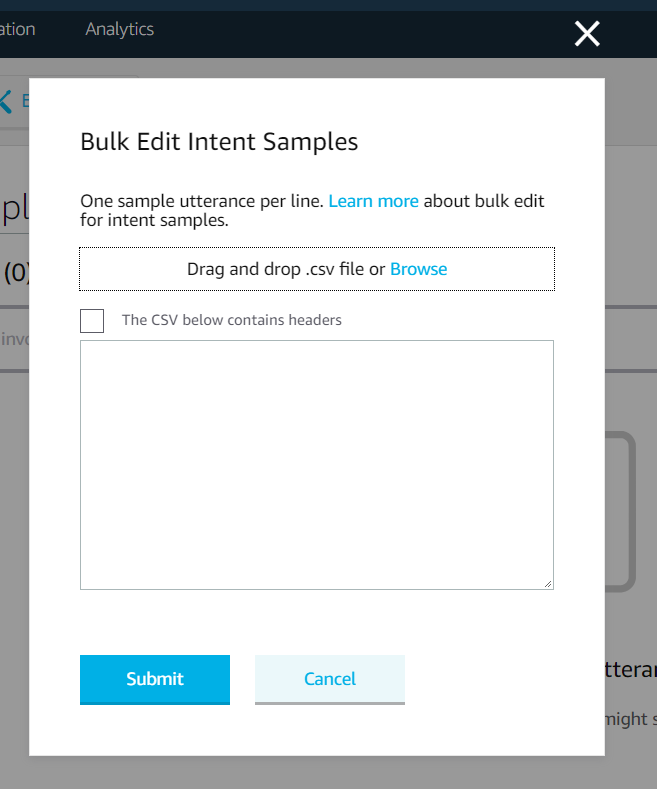
- Browse for or drag and drop the previously made CSV and it will populate the text field.
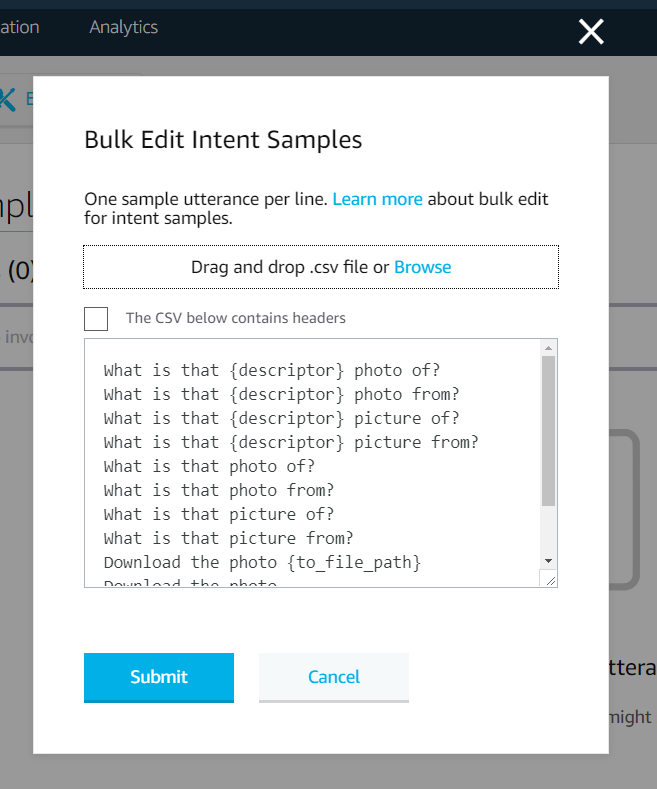
- Press "Submit" and the utterances field will be filled.
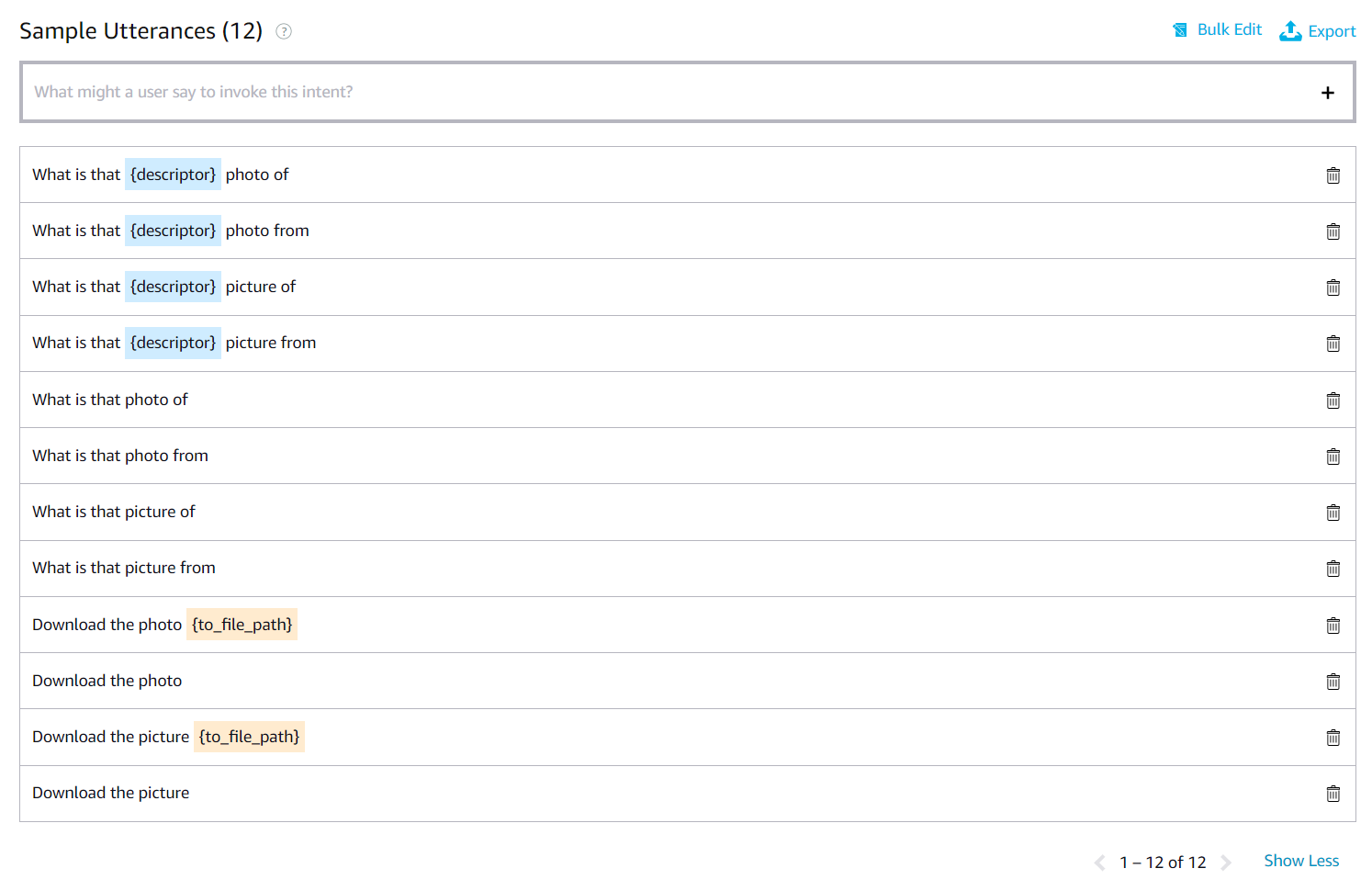
And that's it, no need to manually type in potentially hundreds or thousands of annoyingly similar phrases.
Other Features
- You can add utterance templates after making the class like so:
from utter_more import UtterMore
um = UtterMore()
um.add_utterance_template("What (is*s|are*p) (that^s|those^p) {{descriptor}} (photo|picture)(^s|s^p) (of|from)")
um.add_utterance_template("Download the (photo|picture) {{to_file_path}}")
um.iter_build_utterances()
um.save_for_alexa(PATH_TO_DIRECTORY, FILE_NAME)This will produce the same CSV as above
- Continuing with the above code, you can then save these utterances normally as either a regular CSV or a text file like so:
# Saves as utterances.txt with new line separators
um.save_utterances(PATH_TO_DIRECTORY, 'utterances', 'txt')
# Saves as utterances.csv as actual comma-separated values
um.save_utterances(PATH_TO_DIRECTORY, 'utterances', 'csv')- Utterances can be created from a template without adding it to the UtterMore object so
from pprint import pprint
from utter_more import UtterMore
um = UtterMore()
utterances = um.build_utterance("What (is*s|are*p) (that^s|those^p) {{descriptor}} (photo|picture)(^s|s^p) (of|from)")
pprint(utterances)will output:
[['What is that {descriptor} photo of',
'What is that {descriptor} photo from',
'What is that {descriptor} picture of',
'What is that {descriptor} picture from',
'What is that photo of',
'What is that photo from',
'What is that picture of',
'What is that picture from',
'What are those {descriptor} photos of',
'What are those {descriptor} photos from',
'What are those {descriptor} pictures of',
'What are those {descriptor} pictures from',
'What are those photos of',
'What are those photos from',
'What are those pictures of',
'What are those pictures from']]