![]()




![]()
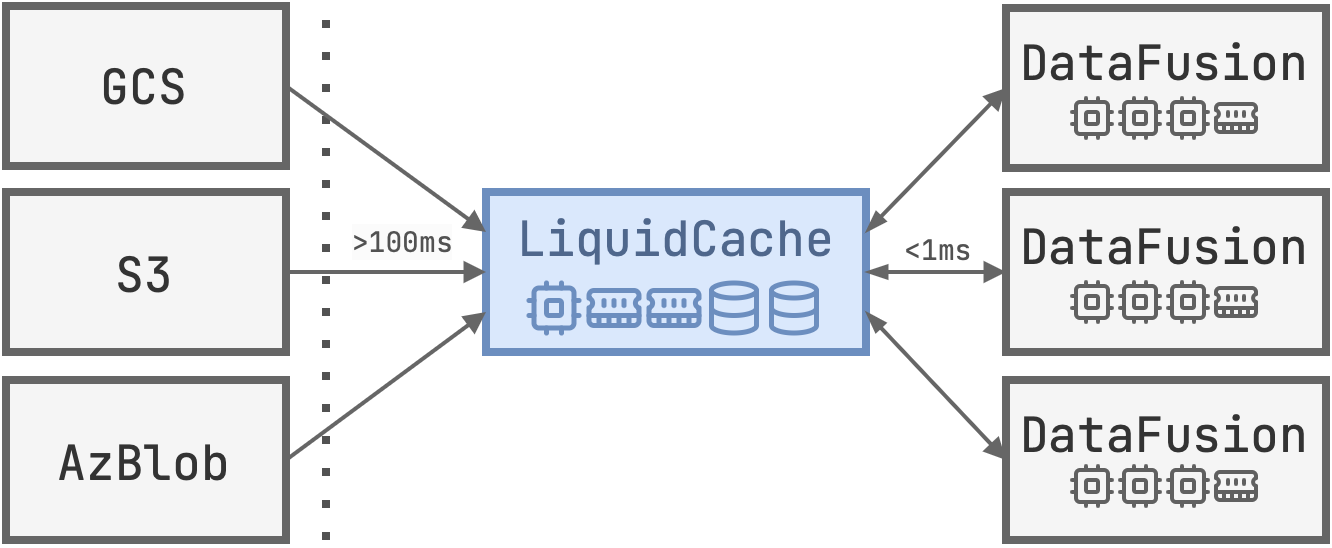
LiquidCache is a pushdown cache for S3 -- projections, filters, and aggregations are evaluated at the cache server before sending to DataFusion. LiquidCache is a research project funded by InfluxData, SpiralDB, and Bauplan.
LiquidCache is a radical redesign of caching: it caches logical data rather than its physical representations.
This means that:
- LiquidCache transcodes S3 data (e.g., JSON, CSV, Parquet) into an in-house format -- more compressed, more NVMe friendly, more efficient for DataFusion operations.
- LiquidCache returns filtered/aggregated data to DataFusion, significantly reducing network IO.
Cons:
- LiquidCache is not a transparent cache (consider Foyer instead), it leverages query semantics to optimize caching.
Multiple DataFusion nodes share the same LiquidCache instance through network connections. Each component can be scaled independently as the workload grows.
Check out the examples folder for more details.
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
let liquid_cache = LiquidCacheService::new(
SessionContext::new(),
Some(1024 * 1024 * 1024), // max memory cache size 1GB
Some(tempfile::tempdir()?.into_path()), // disk cache dir
)?;
let flight = FlightServiceServer::new(liquid_cache);
Server::builder()
.add_service(flight)
.serve("0.0.0.0:15214".parse()?)
.await?;
Ok(())
}Add the following dependency to your existing DataFusion project:
[dependencies]
liquid-cache-client = "0.1.0"Then, create a new DataFusion context with LiquidCache:
#[tokio::main]
pub async fn main() -> Result<()> {
let ctx = LiquidCacheBuilder::new(cache_server)
.with_object_store(ObjectStoreUrl::parse(object_store_url.as_str())?, None)
.with_cache_mode(CacheMode::Liquid)
.build(SessionConfig::from_env()?)?;
let ctx: Arc<SessionContext> = Arc::new(ctx);
ctx.register_table(table_name, ...)
.await?;
ctx.sql(&sql).await?.show().await?;
Ok(())
}If you are uncomfortable with a dedicated server, LiquidCache also provides an in-process mode.
use datafusion::prelude::SessionConfig;
use liquid_cache_parquet::{
LiquidCacheInProcessBuilder,
common::{LiquidCacheMode},
};
use liquid_cache_parquet::policies::{CachePolicy, DiscardPolicy};
use tempfile::TempDir;
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
let temp_dir = TempDir::new().unwrap();
let (ctx, _) = LiquidCacheInProcessBuilder::new()
.with_max_cache_bytes(1024 * 1024 * 1024) // 1GB
.with_cache_dir(temp_dir.path().to_path_buf())
.with_cache_mode(LiquidCacheMode::Liquid {
transcode_in_background: true,
})
.with_cache_strategy(Box::new(DiscardPolicy))
.build(SessionConfig::new())?;
ctx.register_parquet("hits", "examples/nano_hits.parquet", Default::default())
.await?;
ctx.sql("SELECT COUNT(*) FROM hits").await?.show().await?;
Ok(())
}See dev/README.md
LiquidCache requires a few non-default DataFusion configurations:
ListingTable:
let (ctx, _) = LiquidCacheInProcessBuilder::new().build(config)?;
let listing_options = ParquetReadOptions::default()
.to_listing_options(&ctx.copied_config(), ctx.copied_table_options());
ctx.register_listing_table("default", &table_path, listing_options, None, None)
.await?;Or register Parquet directly:
let (ctx, _) = LiquidCacheInProcessBuilder::new().build(config)?;
ctx.register_parquet("default", "examples/nano_hits.parquet", Default::default())
.await?;For performance testing, disable background transcoding:
let (ctx, _) = LiquidCacheInProcessBuilder::new()
.with_cache_mode(LiquidCacheMode::Liquid {
transcode_in_background: false,
})
.build(config)?;LiquidCache is optimized for x86-64 with specific instructions. ARM chips (e.g., Apple Silicon) use fallback implementations. Contributions welcome!
Not yet. While production readiness is our goal, we are still implementing features and polishing the system. LiquidCache began as a research project exploring new approaches to build cost-effective caching systems. Like most research projects, it takes time to mature, and we welcome your help!
Check out our paper (to appear in VLDB 2026) for more details. Meanwhile, we are working on a technical blog to introduce LiquidCache in a more accessible way.
We are always looking for contributors! Any feedback or improvements are welcome. Feel free to explore the issue list and contribute to the project. If you want to get involved in the research process, feel free to reach out.
LiquidCache is a research project funded by:
- SpiralDB
- InfluxData
- Bauplan
- Taxpayers of the state of Wisconsin and the federal government.
As such, LiquidCache is and will always be open source and free to use.
Your support for science is greatly appreciated!





![github-actions[bot]](https://avatars.githubusercontent.com/u/41898282?size=120)







