Thinktool
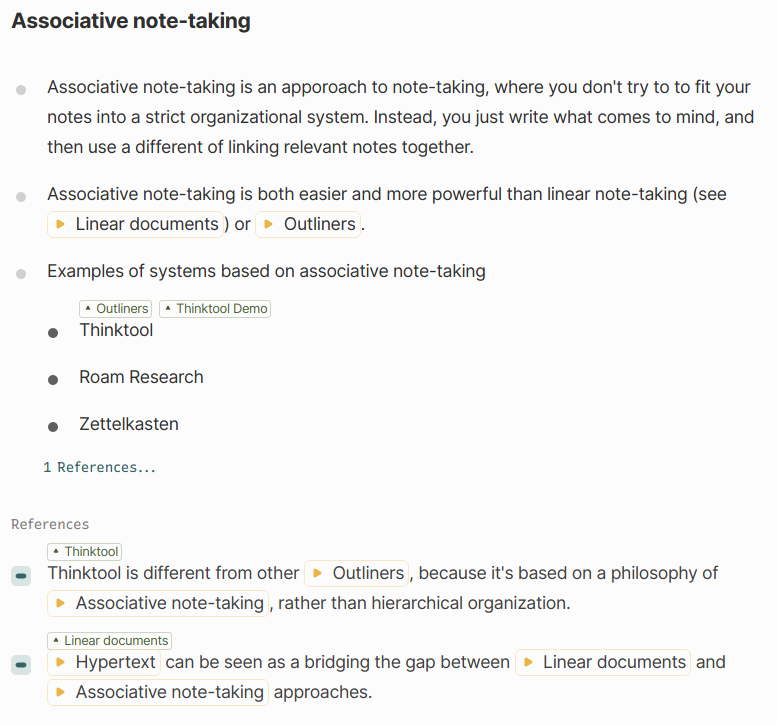
This repository contains the source code of Thinktool, an associative note-taking application inspired by TheBrain and Roam Research.
Check out the demo in your browser here!
(Screenshot showing links, backreferences and multiple parents.)
Project status
Development on Thinktool is quite slow, since I'm only working on it in my free time.
As of May 2022, I'm currently spending most of my time working on another side-project, namely Nextool (source code), but I intend to come back to Thinktool soon.
I'm currently reconsidering the typical approach to implementing "digital Zettelkasten" after watching some of Scott Scheper's really interesting videos on his Antinet. In particular, I've been experimenting (in Obsidian) with a formal system for a note-taking system that consists of two parts: a large, append-only database of immutable notes, and a small, mutable index. My current opinion is that making notes immutable may be important for long-term note-taking systems.
I'm thinking about how I want to implement these ideas in Thinktool, but haven't yet decided on anything concrete. Most likely, the next major update to Thinktool, will have some first-class concenpt of a single "note" (as opposed to just a graph of bullet points), will let you distinguish between different "versions" of a note, and will have at least two different "sections" for mutable vs. immutable notes ("library" vs. "index", for example).
My long-term main areas of focus are general UX and "learnability", and improving the desktop client and offline-only support for improved privacy and data security. There is no specific roadmap or time estimates.
The website and newsletter haven't been updated in a while, although I do intend to come back to them. If you want to follow Thinktool's development, watch this repository.
Comparison to other software
Offline client: Obsidian and Logseq have excellent offline clients, which let you store your data in Markdown files locally. Thinktool does have an offline desktop client, but it's janky in comparison and uses a SQLite database for data storage.
Graph structure: Roam Research, Logseq and Obsidian let you link different pages together and use that graph structure to explore your notes. However, only pages -- not individual items -- can be connected like this. In contrast, Thinktool lets you connect individual items to multiple parents, so the same item can exist in multiple places.
Transclusion: To work around the issue of connecting individual items, Roam Research and Logseq support embedding (transcluding) blocks. However, recursive transclusion is not supported, and transclusions are second-class. Thinktool doesn't need transclusion, because the same item can simply exist in multiple places -- there is no difference between the "original" item and its clones.
Hierarchical structure: If you want to connect pages hierarchically, Roam Research, Logseq and Obsidian require you to create a separate index page where you link the different pages together (or use some other custom system). Thinktool makes no distinction between pages and items, so you can simply add one page as a child of another page.
Bidirectional links: All of these tools, including Thinktool are built around bidirectional linking and have similar features.
Miscellaneous features: Roam Research, and to a lesser extent Logseq, have a bunch of neat features that let you use it for task management, spaced repetition and more. Thinktool is designed just for note-taking, so it doesn't have a lot of extra features.
Ease of use and UI: Even though Thinktool's data model is arguably simpler than these other tools, the UI is quite a bit worse, so it ends up being harder to understand.
Open Source
All content of this repository to which I own the copyright is licensed under the terms of the GNU AGPLv3 or any later version as described in LICENSE.md.
This repository is not currently accepting issues or pull requests. Please see Thinktool's web page for information about how to contact me with your feedback about Thinktool. I may occationally force push to this repository, since I'm not expecting anyone else to be actively working on it. You are welcome to create your own fork.
The instructions in this README are mostly written for myself, and may not be sufficient to compile this project on your own. However, you can find some hints on how to run it in .github/workflows.
You will always be able to compile and use this version of Thinktool for free. The online service hosted at https://thinktool.io may eventually become a subscription service, but it's currently also free, and probably will be for a while.
Deployment
The application consists of three parts:
- Web client in
src/web - Node.js server in
src/server - Electron-based desktop client in
src/desktop
To build the server, run docker build . -f tools/Dockerfile -t thinktool from
the top-level directory, and then run the thinktool image with the environment
variables listed below.
Static Resources
To build the web client, run yarn install --frozen-lockfile && yarn build from
the src/web directory. This will build the web client into out/, which can
then be deployed as a static website.
Before running this command, set the following environment variables:
-
DIAFORM_API_HOST— API server host, including the protocol, e.g.https://api.thinktool.io. -
THINKTOOL_ASSETS_HOST— Host for desktop client, including the protocol, e.g.https://assets.thinktool.io.
Desktop
The desktop client can currently be built for Linux and Windows. We're planning on supporting macOS in the future. It must be built on the same platform that is being targeted.
Start by setting the following environment variables:
-
DIAFORM_API_HOST— API server host, including the protocol, e.g.https://api.thinktool.io.
Then enter the src/desktop directory and run yarn install --frozen-lockfile.
Build the Linux client with yarn bundle-linux or the Windows client with
yarn bundle-windows.
When developing the desktop client, you can use this command to somewhat hackily use the local build of the client package:
cp -r ../client/dist/* node_modules/@thinktool/client/dist/ && yarn bundle-linux
Server
The server uses a PostgreSQL database. Set the following environment variables before running the server:
-
DIAFORM_POSTGRES_HOST— The hostname containing the database, e.g.localhost -
DIAFORM_POSTGRES_PORT— Port that the database is running on, e.g.5432 -
DIAFORM_POSTGRES_USERNAME— Username used to authenticate with the PostgreSQL DB, e.g.postgres -
DIAFORM_POSTGRES_PASSWORD— Password used to authenticate with the PostgreSQL DB, e.g.postgres
You will need to manually set up the database schema. See tools/db/_initialize.sql, though this may be outdated.
For sending emails (used for "Forgot my password" functionality), we use Mailgun. Configure the following environment variables:
-
MAILGUN_API_KEY— API key
Additionally, the server expects the following environment variables to be set:
-
DIAFORM_STATIC_HOST— Base URL of the server hosting static resources, e.g.https://thinktool.io
Build the server as a Docker image:
# docker build -t thinktool -f tools/Dockerfile .
Once you have the thinktool image, run it with the environment variables given above:
# docker run \
-e DIAFORM_POSTGRES_HOST \
-e DIAFORM_POSTGRES_PORT \
-e DIAFORM_POSTGRES_USERNAME \
-e DIAFORM_POSTGRES_PASSWORD \
-e MAILGUN_API_KEY \
-e DIAFORM_STATIC_HOST \
-p 80:80 \
thinktool
Static website
The website is built using NextJS and hosted using
Vercel. It is automatically rebuilt from the src/web
directory whenever the website branch is pushed.
As with the desktop client, there is a hacky solution for using the current local client package build while working on the website:
cp -r ../client/dist/* node_modules/@thinktool/client/dist/ && rm -r .next && yarn dev
Development
While working on Thinktool, most changes should be made in the src/client
directory, since this is the package that's used for both the web client and the
desktop client. Enter the src/client directory and run yarn install --frozen-lockfile
and use yarn webpack serve --open --config webpack.dev.js to continually rebuild.
Releasing new client version
When you are ready to push out a client-side update, run
tools/dev/release-client.sh <client-version>. This will bump the version number to
<client-version>, publish the package, and also update the relevant dependency in
the web and desktop clients.
Manually update the version number in the package.json for the desktop
package, commit the changes, tag the commit with a tag of the form x.y.z and
push to GitHub. A workflow should automatically create a GitHub release; manually
update this release with the release notes.
Note that the tag should be the same as the desktop client version, while the version number for the client package may be different!

![dependabot[bot]](https://avatars.githubusercontent.com/u/49699333?size=120)