模糊聚类算法工具箱(python)
introduce
本开源项目为模糊聚类算法python代码,主要算法包括:
- FCM(模糊C均值算法)
- MEC (极大熵模糊聚类算法)
- KFCM(核模糊聚类算法)
- SFCM (半监督模糊聚类算法)
- eSFCM (基于信息熵的半监督模糊聚类算法)
- SMUC (基于度量学习与信息熵的半监督模糊聚类算法)
以这些算法为基础的相关论文可参考本人的谷歌学术主页:Wei Cai,Guangdong University of Technology
install
通过以下方式安装(win10用户安装好python并配置好环境变量之后,打开cmd输入以下命令):
pip install FuzzyClustering
project structure
- dataset:数据集
- ClusterAidedComputing.py :包括聚类常用的一些函数
- ClusteringIteration.py :包括聚类算法迭代式
- FuzzyClustering.py :模糊聚类算法
- demo.py : 演示脚本(运行此程序)
算法调用
参数
(以下为所有模糊聚类算法都有的参数)
data :数据集,统一使用数组(darry)
cluster_n :类簇中心数
max_iter :最大迭代次数
e :目标函数值变化最小阈值
printOn :打印迭代情况开关(当printOn=1时打印迭代情况)
调用规则
所有的函数都需要输入data和cluster_n,其余参数可能有预设参数(若有预设参数则可以不输入,不输入则采用默认参数)
算法函数
- FCM
U,V,obj_fcn = fcm(data,cluster_n,m = 2,max_iter = 1000,e = 0.00001,printOn = 1)或
U,V,obj_fcn = fcm(data,cluster_n)如上,m ,max_iter,e ,printOn这四个参数已有默认参数,可不设置
- MEC
U,V,obj_fcn = mec(data,cluster_n,gamma=0.01,max_iter = 1000,e = 0.00001,printOn = 1)gamma :惩罚系数
-
KFCM
sigma :高斯核标准差
lamda :惩罚系数
kfcm(data,cluster_n,sigma=2,m=2,lamda=0.1,max_iter = 1000,e = 0.00001,printOn = 1)- SFCM
U,V,obj_fcn = sfcm(data,cluster_n,label,m = 2,max_iter = 1000,e = 0.00001,alpha=5,printOn = 1)label :标签(array格式)
- eSFCM
U,V,obj_fcn = esfcm(data,cluster_n,label,max_iter = 1000,e = 0.00001,lamda=1,printOn = 1)- SMUC
U,V,obj_fcn = smuc(data,cluster_n,label,max_iter = 1000,e = 0.5,lamda=1,printOn = 1)
demo
import FuzzyClustering
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import accuracy_score
'''数据及参数设置'''
data_route = r'dataset\iris.csv'
label_route = r'dataset\irislabel.csv'
with open(data_route,encoding = 'utf-8') as f:
data = np.loadtxt(f,delimiter = ",")
with open(label_route,encoding = 'utf-8') as f:
label = np.loadtxt(f,delimiter = ",")
cluster_n = int(np.max(label))
data = ( data - np.min(data,axis=0)) / (np.max(data,axis=0) - np.min(data,axis=0)) #数据标准化
'''模糊聚类算法'''
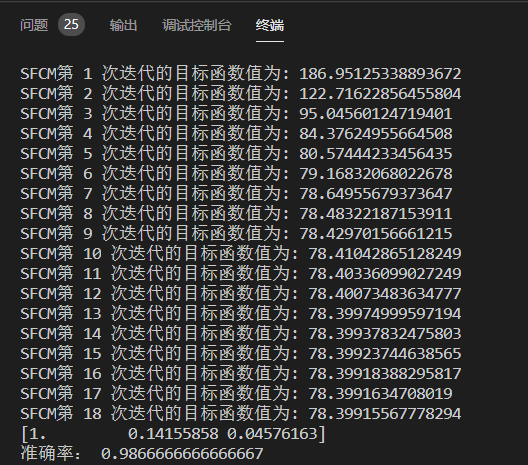
U,center,fcm_obj_fcn = FuzzyClustering.smuc(data,cluster_n,label[1:20],max_iter = 100,e = 0.00001,lamda=0.5,printOn = 1)
label_pred,abaaba = np.where(U==np.max(U,axis=0)) #最大值索引
'''画图'''
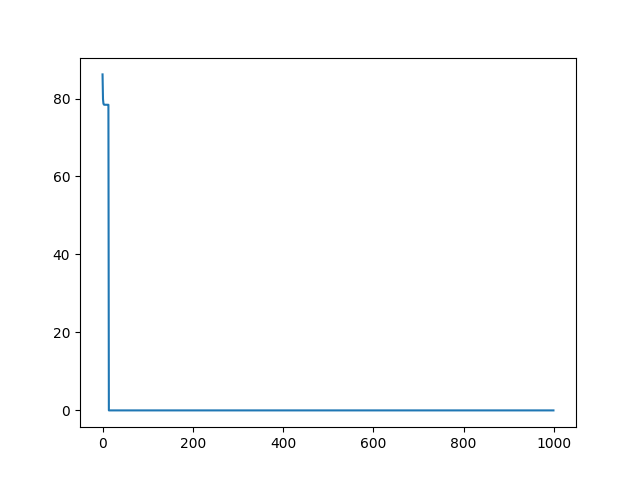
plt.plot(fcm_obj_fcn)
plt.show()
'''性能评价'''
label_pred = label_pred + 1 #因为索引是从零开始,但标签是从1开始
print(U[:,1])
print("准确率:",accuracy_score(label.tolist(),label_pred.tolist()))迭代目标函数值变化图: