This package implements the mathematical model of the "Multi Port Stowage Planning" (MPSP) problem, introduced in Avriel et al. 1998, as a reinforcement learning environment using the Gymnasium API.
The Env class has the following input parameters:
- R (int): number of rows
- C (int): number of columns
- N (int): number of ports
The env observations consist of a dictionary with the one hot encoded bay, and the upper triangular part of the transportation matrix as a flattened array.
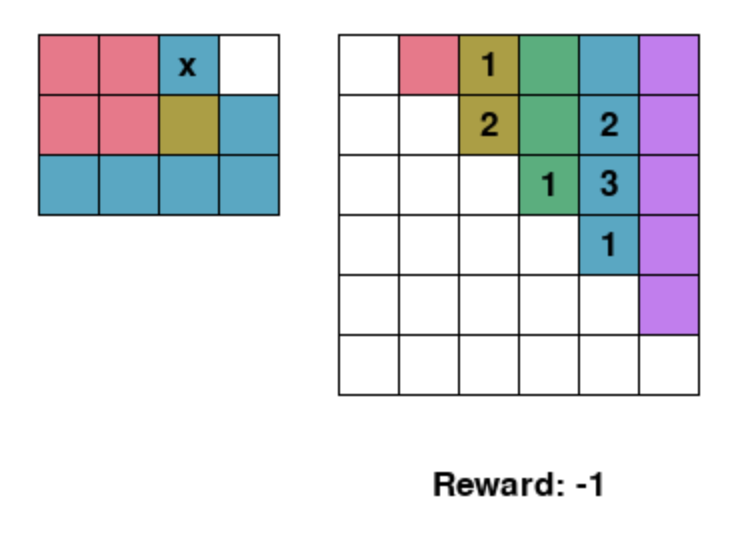 Screenshot from the environment. The left matrix is the bay, and the right matrix is the transportation matrix. "x" denotes blocking containers. The reward decreases by one for each reshuffle necessitated by the agents stowage plan.
Screenshot from the environment. The left matrix is the bay, and the right matrix is the transportation matrix. "x" denotes blocking containers. The reward decreases by one for each reshuffle necessitated by the agents stowage plan.
Note that since the mathematical model disregards any stability constraints, the env automatically swaps the column order in a lexocographic manor, based on the containers in the columns. This reduces the state space, by a factor of almost
When using the environment, you should call env.close() before exiting your program, to avoid memory leaks.
Minimal usage with Stable Baselines:
from MPSPEnv import Env
from sb3_contrib.ppo_mask import MaskablePPO
train_env = Env(R=8, C=4, N=5)
model = MaskablePPO(
"MultiInputPolicy",
train_env
)
model.learn(
total_timesteps=1e6,
progress_bar=True
)
train_env.close()If you wish to try the env yourself, placing containers using keys 0-3 and removing containers using keys 4-7, you can use the following script:
from MPSPEnv import Env
import pygame, numpy as np
def get_action_from_key(key):
return key - pygame.K_0 if pygame.K_0 <= key <= pygame.K_7 else None
if __name__ == "__main__":
env = Env(3, 4, 6)
env.reset()
while True:
env.render()
for event in pygame.event.get():
if event.type == pygame.QUIT:
env.close()
exit()
elif (
event.type == pygame.KEYDOWN
and (action := get_action_from_key(event.key)) is not None
):
_, reward, done, _, _ = env.step(action)
if done:
env.render()
pygame.time.wait(1000)
env.close()
exit()
pygame.time.wait(10)
