Badfish - A missing data wrangling library in Python
Badfish introduces MissFrame, a wrapper over pandas DataFrame, to wrangle through and investigate missing data. It opens an easy to
use API to summarize and explore patterns in missingness.
Badfish provides methods which make it easy to investigate any systematic issues in data wrangling, surveys, ETL processes which can lead to missing data.
The API has been inspired by typical questions which arise when exploring missing data.
Badfish uses the where and how api in most of its methods to prepare a subset of the data to work on.
where : Work on a subset of data where specified columns are missing.
how : Either all | any of the columns should be missing.
Eg. mf.counts(columns = ['Age', 'Gender']) would give counts of missing values in the entire dataset.
While, mf.counts(where=['Income'], columns = ['Age', 'Gender']) would give counts of missing values in subset of data where
Income is already missing.
Installation
pip install badfish
Usage
>>> import badfish as bf
>>> mf = bf.MissFrame(df)
Example
Will add an exmaple IPython notebook soon.
Counts
Basic counts of missing data per column.
>>> mf.counts(where=['gender', 'age'], how='all', columns=['Income', 'Marital Status'])
Pattern
Get counts on different combinations of columns with missing data. True means missing and False means present.
>>> mf.pattern()
The same can be visualized in the form of a plot (inspired by VIM package in R)
>>> mf.plot(kind='pattern')
Example plot:
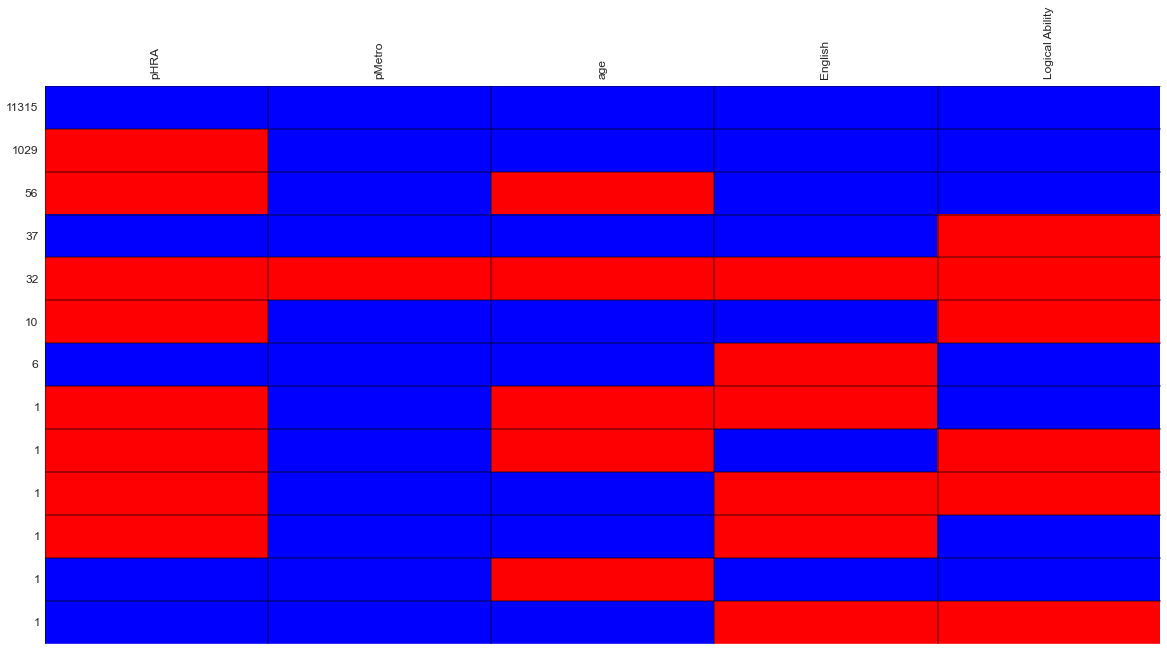
Note: Both where and how can be used in this method.
Itemset Mining
Use frequency item set mining to find subgroups where data goes missing together. Note: This uses the PyMining package.
>>> itemsets, rules = mf.frequency_item_set()
Cohort
Tries to find signigicant group differences between values of columns other than the ones specified in the group clause. Group
made on the basis of missing or non-missing of columns in the group clause. Internally uses scipy.stats.ttest_ind.
This method works on the values in each column instead of column names.
Note: Experimental method.
>>> mf.cohort(group=['gender'], columns=['Income'])
License
Please see the repository license.
Generally, we have licensed badfish to make it as widely usable as possible.
Call for contribution
If you have any ideas, issues or feature requests, feel free to open an issue, send a PR or contact us.

