

![]()

An interactive environment for modular feature engineering, experiment tracking, feature selection and stacking.
Install KTS with pip install kts. Compatible with Python 3.6+.
Modular Feature Engineering
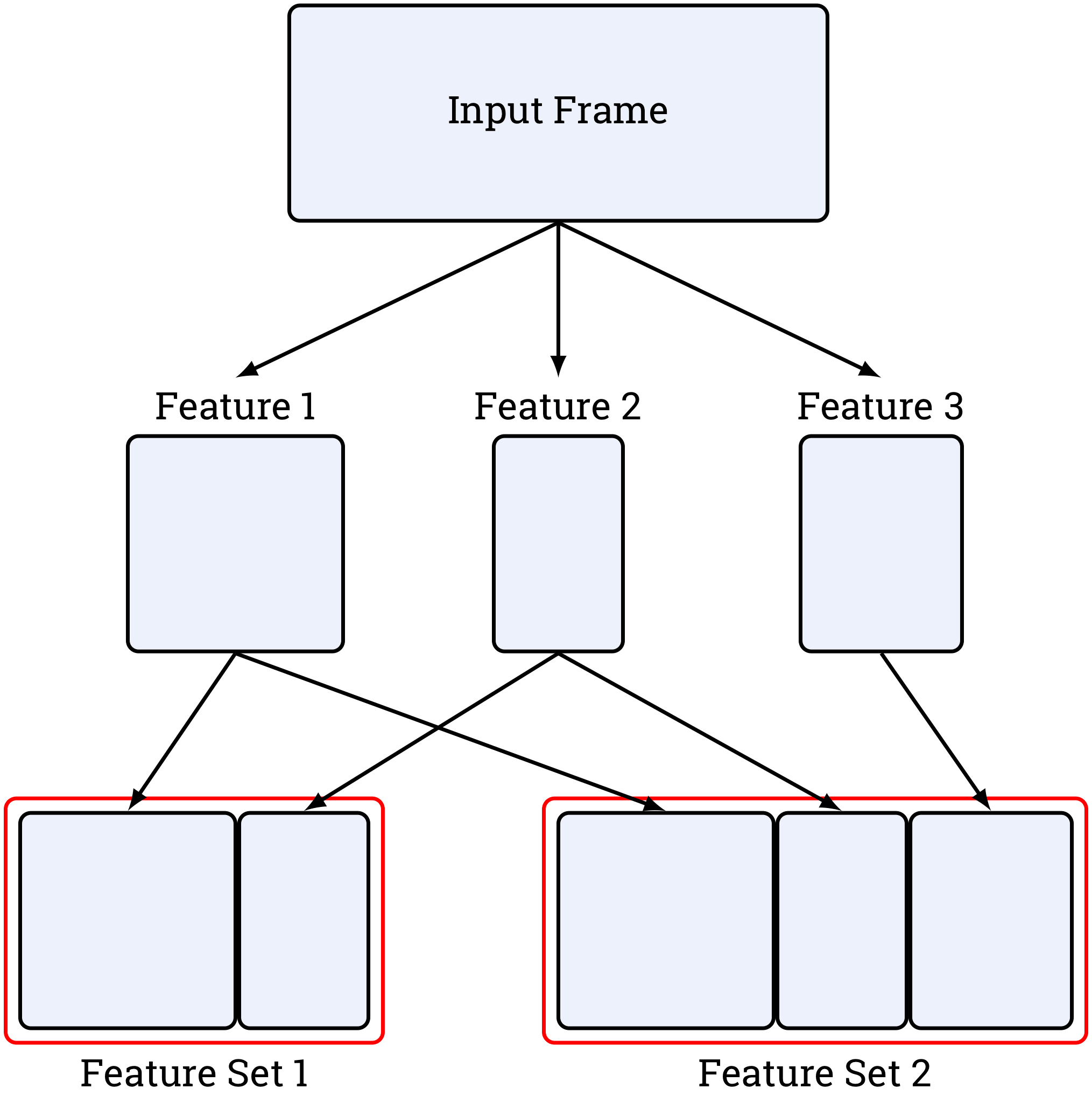
Define features as independent blocks to organize your projects.
Source Code Tracking

Track source code of every feature and experiment to make each of them reproducible.
Parallel Computing and Caching

Compute independent features in parallel. Cache them to avoid repeated computations.
Experiment Tracking
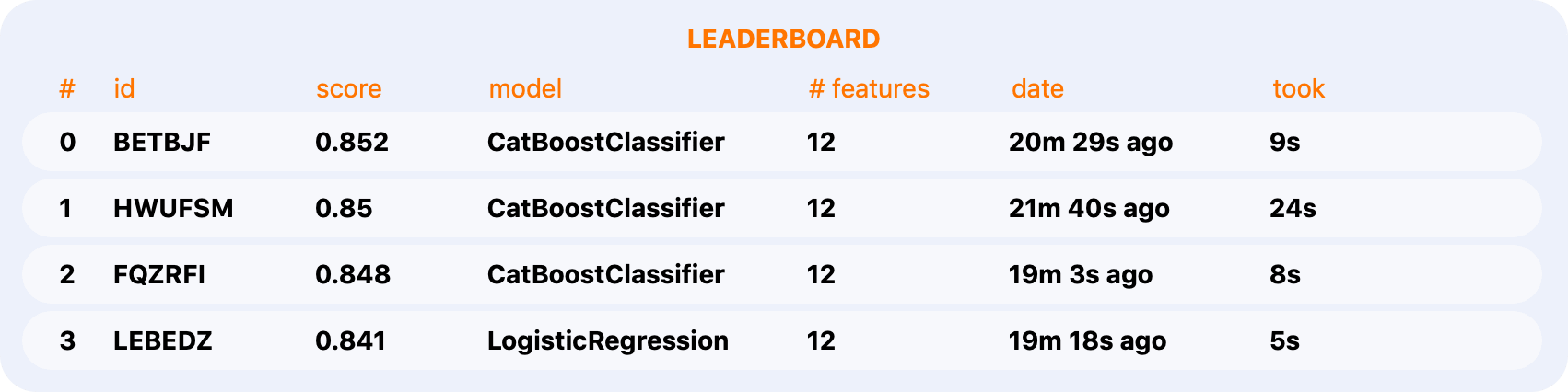
Track your progress with local leaderboards.
Feature Selection
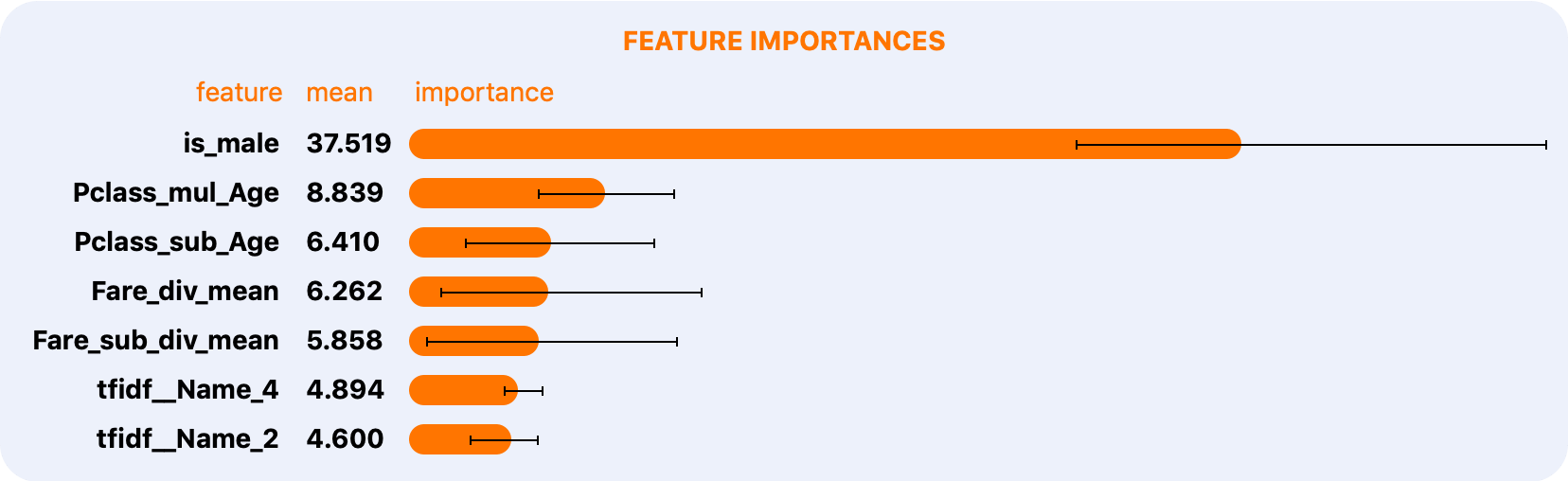
Compute feature importances and select features from any experiment
with experiment.feature_importances() and experiment.select().
Interactivity and Rich Reports
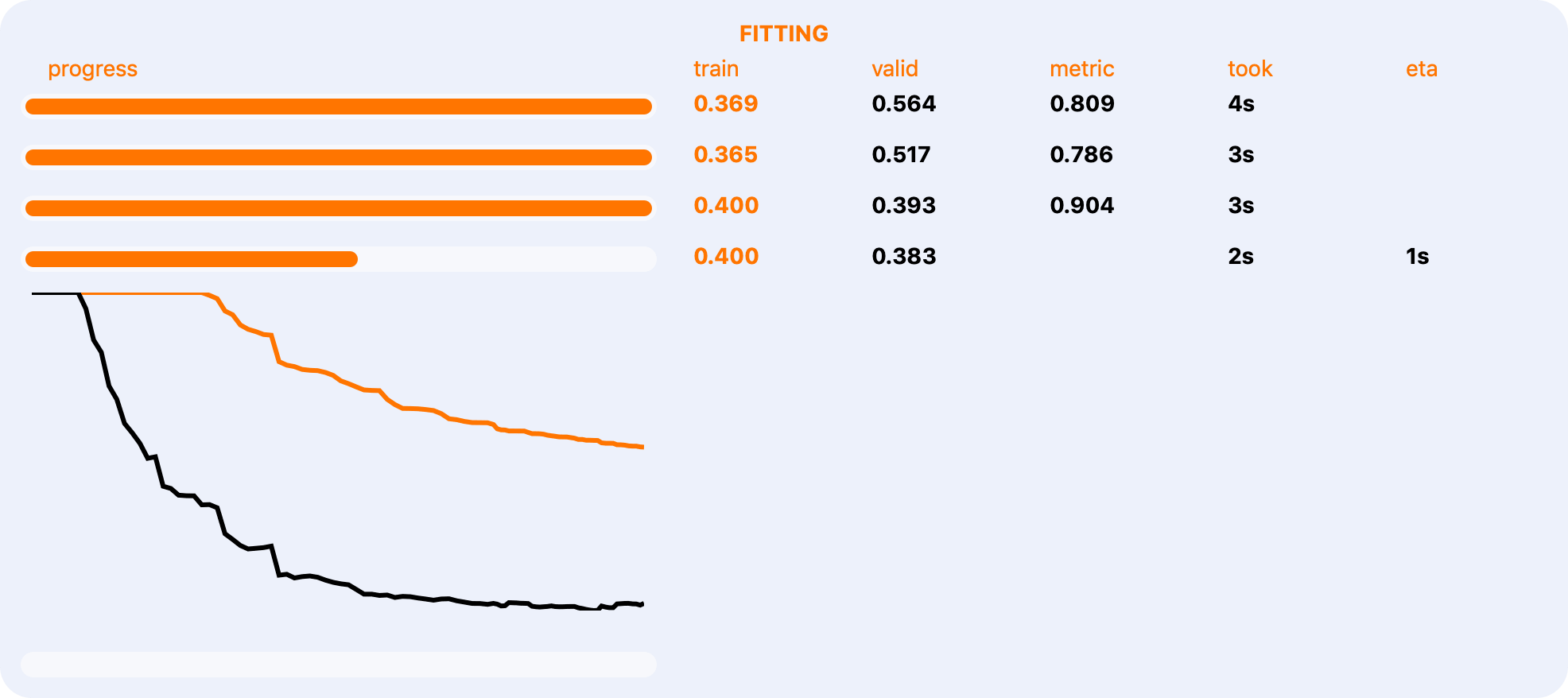
Monitor the progress of everything going on in KTS with our interactive reports.
From model fitting to computing feature importances.
Getting Started
Titanic Tutorial
Start exploring KTS with tutorial based on Titanic dataset. Run notebooks interactively in Binder or just read them in NBViewer.
1. Feature Engineering
- Modular Feature Engineering in 30 seconds
- Decorators reference
- Feature Types
- Standard Library
- Feature Set
2. Modelling
3. Stacking
Documentation
Check out docs.kts.ai for a more detailed description of KTS features and interfaces
Inline Docs
Most of our functions and classes have rich docstrings. Read them right in your notebook, without interruption.
Acknowledgements
MVP of the project was designed and implemented by the team of Mikhail Andronov, Roman Gorb and Nikita Konodyuk under the mentorship of Alexander Avdyushenko during a project practice held by Yandex and Higher School of Economics on 1-14 February 2019 at Educational Center «Sirius».


