![]()
![]()
KALE (Kubeflow Automated pipeLines Engine) is a project that aims at simplifying the Data Science experience of deploying Kubeflow Pipelines workflows.
Kubeflow is a great platform for orchestrating complex workflows on top Kubernetes and Kubeflow Pipeline provides the mean to create reusable components that can be executed as part of workflows. The self-service nature of Kubeflow make it extremely appealing for Data Science use, at it provides an easy access to advanced distributed jobs orchestration, re-usability of components, Jupyter Notebooks, rich UIs and more. Still, developing and maintaining Kubeflow workflows can be hard for data scientists, who may not be experts in working orchestration platforms and related SDKs. Additionally, data science often involve processes of data exploration, iterative modelling and interactive environments (mostly Jupyter notebook).
Kale bridges this gap by providing a simple UI to define Kubeflow Pipelines workflows directly from you JupyterLab interface, without the need to change a single line of code.
Read more about Kale and how it works in this Medium post: Automating Jupyter Notebook Deployments to Kubeflow Pipelines with Kale
Getting started
Install the Kale backend from PyPI and the JupyterLab extension. You can find a set of curated Notebooks in the examples repository
# install kale
pip install kubeflow-kale
# install jupyter lab
pip install "jupyterlab>=2.0.0,<3.0.0"
# install the extension
jupyter labextension install kubeflow-kale-labextension
# verify extension status
jupyter labextension list
# run
jupyter lab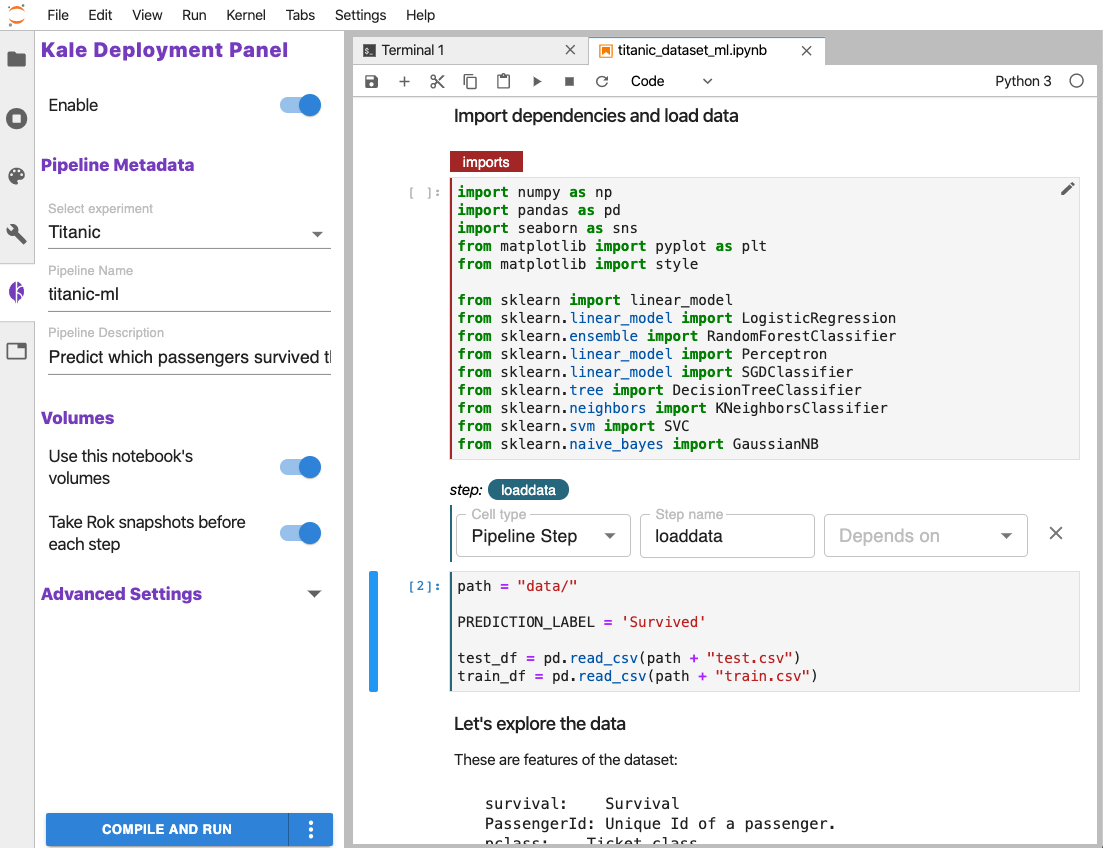
To build images to be used as a NotebookServer in Kubeflow, refer to the
Dockerfile in the docker folder.
FAQ
Head over to FAQ to read about some known issues and some of the limitations imposed by the Kale data marshalling model.
Resources
- Kale introduction blog post
- Codelabs showcasing Kale working in MiniKF with Arrikto's Rok:
- KubeCon NA Tutorial 2019: From Notebook to Kubeflow Pipelines: An End-to-End Data Science Workflow / video
- CNCF Webinar 2020: From Notebook to Kubeflow Pipelines with MiniKF & Kale / video
- KubeCon EU Tutorial 2020: From Notebook to Kubeflow Pipelines with HP Tuning: A Data Science Journey / video
Contribute
Backend
Create a new Python virtual environment with Python >= 3.6. Then:
cd backend/
pip install -e .[dev]
# run tests
pytest -x -vvLabextension
The JupyterLab Python package comes with its own yarn wrapper, called jlpm.
While using the previously installed venv, install JupyterLab by running:
pip install "jupyterlab>=2.0.0,<3.0.0"You can then run the following to install the Kale extension:
cd labextension/
# install dependencies from package.lock
jlpm install
# build extension
jlpm run build
# list installed jp extensions
jlpm labextension list
# install Kale extension
jlpm labextension install .
# for development:
# build and watch
jlpm run watch
# in another shell, run JupyterLab in watch mode
jupyter lab --no-browser --watchGit Hooks
This repository uses husky to set up git hooks.
For husky to function properly, you need to have yarn installed and in your
PATH. The reason that is required is that husky is installed via
jlpm install and jlpm is a yarn wrapper. (Similarly, if it was installed
using the npm package manager, then npm would have to be in PATH.)
Currently installed git hooks:
-
pre-commit: Run a prettier check on staged files, using pretty-quick







![dependabot[bot]](https://avatars.githubusercontent.com/u/49699333?size=120)

