


Is A Fast & Friendly Web Framework For Building Async APIs With Python 3.10+
![]()
📚 Full Documentation: PantherPy.GitHub.io
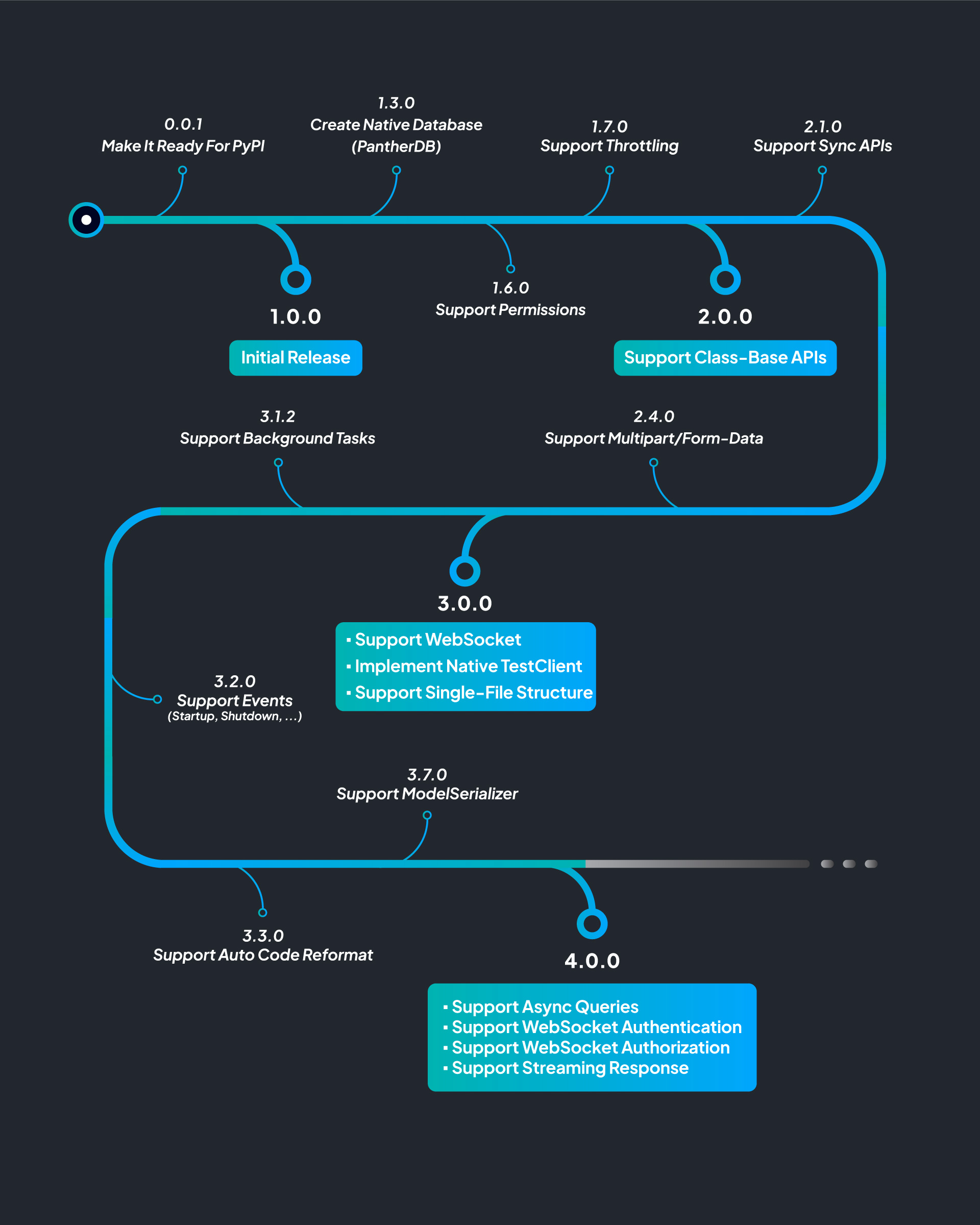
- Include Simple File-Base Database (PantherDB)
- Built-in Document-oriented Databases ODM (MongoDB, PantherDB)
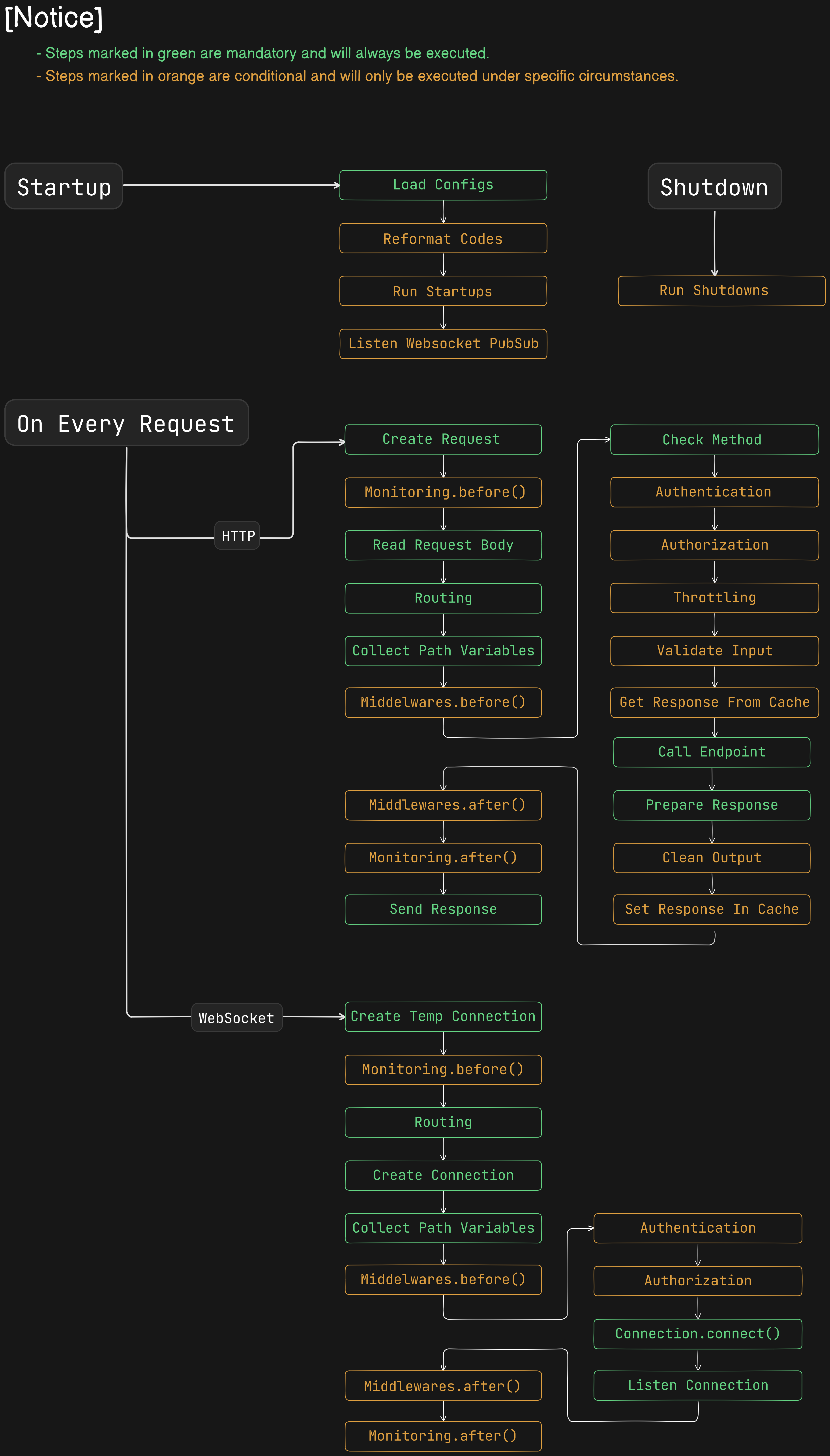
- Built-in Websocket Support
- Built-in API Caching System (In Memory, Redis)
- Built-in Authentication Classes
- Built-in Permission Classes
- Built-in Visual API Monitoring (In Terminal)
- Support Custom Background Tasks
- Support Custom Middlewares
- Support Custom Throttling
- Support Function-Base and Class-Base APIs
- It's One Of The Fastest Python Framework (Benchmark)

$ pip install panther-
$ panther create
-
$ panther run --reload
* Panther uses Uvicorn as ASGI (Asynchronous Server Gateway Interface) but you can run the project with Granian, daphne or any ASGI server
-
$ panther monitor
-
$ panther shell
-
Create
main.pyfrom datetime import datetime, timedelta from panther import status, Panther from panther.app import GenericAPI from panther.response import Response class FirstAPI(GenericAPI): # Cache Response For 10 Seconds cache = True cache_exp_time = timedelta(seconds=10) def get(self): date_time = datetime.now().isoformat() data = {'detail': f'Hello World | {date_time}'} return Response(data=data, status_code=status.HTTP_202_ACCEPTED) url_routing = {'': FirstAPI} app = Panther(__name__, configs=__name__, urls=url_routing)
-
Run the project:
$ panther run --reload
-
Checkout the http://127.0.0.1:8000/
-
Create
main.pyfrom panther import Panther from panther.app import GenericAPI from panther.response import HTMLResponse from panther.websocket import GenericWebsocket class FirstWebsocket(GenericWebsocket): async def connect(self, **kwargs): await self.accept() async def receive(self, data: str | bytes): await self.send(data) class MainPage(GenericAPI): def get(self): template = """ <input type="text" id="messageInput"> <button id="sendButton">Send Message</button> <ul id="messages"></ul> <script> var socket = new WebSocket('ws://127.0.0.1:8000/ws'); socket.addEventListener('message', function (event) { var li = document.createElement('li'); document.getElementById('messages').appendChild(li).textContent = 'Server: ' + event.data; }); function sendMessage() { socket.send(document.getElementById('messageInput').value); } document.getElementById('sendButton').addEventListener('click', sendMessage); </script> """ return HTMLResponse(template) url_routing = { '': MainPage, 'ws': FirstWebsocket, } app = Panther(__name__, configs=__name__, urls=url_routing)
-
Run the project:
$ panther run --reload
-
Go to http://127.0.0.1:8000/ and work with your
websocket
Next Step: First CRUD
If you find this project useful, please give it a star ⭐️.








