



Quick-start guide
For detailed documentation, please click the "Read now" button above.
To install this tool:
pip install --upgrade pptreesTo generate a test adder:
from pptrees.AdderForest import AdderForest as forest
width = 9
f = forest(width, alias = "sklansky")
f.hdl('adder.v')
f.gif('adder.gif')Hardware synthesis of arithmetic operations
Arithmetic operations are important. Addition, in particular, is ubiquitous. When a RISC-V processor boots into Linux, for example, roughly 70% of the assembly instructions use addition.
Circuit design involves trade-offs, typically phrased in terms of power vs performance (speed) vs area.
These trade-offs certainly apply to arithmetic operations. Circuits can be very fast and power-hungry, very slow and power-efficient, or anywhere in between.
Moreso, these trade-offs occur on a bit-by-bit basis. If a circuit generates a 64-bit result, each bit of the result can be optimized for power, speed, or area.
Often this becomes essential, as some bits must be processed faster than others.
These trade-offs create a Pareto front of possible circuits, each optimal for a specific situation.
The implementation of such arithmetic circuits is non-trivial, as is the design space, for reasons elaborated upon in the main documentation.
Traditional framework
How can these circuits be generated and explored, especially when it comes to arithmetic operations?
Historically, one particular method for hardware addition has been used and researched since the 1980s.
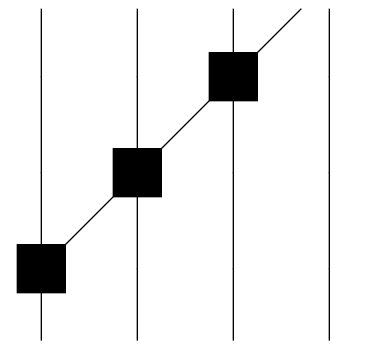
This method conceptualizes circuits using the type of diagram shown below, and is implemented by version v0.4.5 of this library.

The diagram above displays a binary expression graph that performs the desired computation.
The lines in the diagram are edges in the graph, carrying data from the top to the bottom. Each ■ represents a node that performs a simple computation.
This type of diagram, and of implementation, can best be described as an n-rooted binary tree that is drawn upside-down.
There are many ways to design such circuits, and the design space can be explored as seen below.
![]()
Such an exploration is performed by identifying the following three simple patterns throughout the graph, and performing point-targeted transforms.


This method is computationally expensive, requiring exponential run-time.
Moreover, any such exploration using classic diagrams and conceptualization is incomplete and overly complicated.
It is unclear how large the design space, and it is impossible to represent all valid designs.
Under this framework, simple structures become obfuscated, while more advanced optimizations become impossible to implement or theoretically describe.
Arithmetic computation architectures are not n-rooted binary trees.
Revised framework
Instead, this library chooses to express arithmetic computation in terms of forests of n trees.
This approach results directly from the underlying mathematics, allowing circuit designers to leverage decades of research in graph theory and toplogy.
from pptrees.AdderForest import AdderForest as forest
width = 17
f = forest(width, alias = "sklansky")
f
The diagram above displays the same circuit as the one from the previous section.
Each frame of the animation computes an individual bit of the final sum.
It is immediately clear how large the design space is:
from pptrees.util import catalan
width = 17
number_of_designs = 1
for a in range(width):
number_of_designs = number_of_designs * catalan(a)
print(number_of_designs)323828772071827218688291208408423952910530531102720000000
It is straightforward to generate any valid tree in O(n lg(n)) time:
from pptrees.AdderForest import AdderForest as forest
from pptrees.util import catalan_bounds
width = 17
print("The maximum tree sizes for a forest of width {0} are {1}".format(width,catalan_bounds(width)))
f = forest(width, tree_start_points = [0, 0, 0, 2, 5, 37, 74, 214, 214, 670, 2000, 5463, 12351, 135151, 461614, 1512512, 8351854, 3541563])
fThe maximum tree sizes for a forest of width 17 are [0, 0, 1, 4, 13, 41, 131, 428, 1429, 4861, 16795, 58785, 208011, 742899, 2674439, 9694844, 35357669]

Similarly, it is straightforward to label any valid tree in O(n lg(n)) time:
from pptrees.AdderForest import AdderForest as forest
f = forest(width, tree_start_points = [0, 0, 0, 2, 5, 37, 74, 214, 214, 670, 2000, 5463, 12351, 135151, 461614, 1512512, 8351854, 3541563])
for t in enumerate(f.trees):
print("The rank of tree {0} in this forest is {1}".format(t[0],t[1].rank()))The rank of tree 0 in this forest is 0
The rank of tree 1 in this forest is 0
The rank of tree 2 in this forest is 0
The rank of tree 3 in this forest is 2
The rank of tree 4 in this forest is 5
The rank of tree 5 in this forest is 37
The rank of tree 6 in this forest is 74
The rank of tree 7 in this forest is 214
The rank of tree 8 in this forest is 214
The rank of tree 9 in this forest is 670
The rank of tree 10 in this forest is 2000
The rank of tree 11 in this forest is 5463
The rank of tree 12 in this forest is 12351
The rank of tree 13 in this forest is 135151
The rank of tree 14 in this forest is 461614
The rank of tree 15 in this forest is 1512512
The rank of tree 16 in this forest is 8351854
Factorization optimizations such that of Ling, a concept that cannot be described by the old framework, are a straightforward decomposition of the "gp" pre-processing nodes into "g" and "p", followed by a stereoscopic combination of two such tree halves.
Sparseness, another concept that is difficult to understand under the old framework, arises naturally.
Nested sparseness, a novel concept that can reduce the circuits' logical depth, has not been discovered by prior literature due to its incompatibility with the traditional framework.
from pptrees.AdderTree import AdderTree as tree
width = 8
t = tree(width, start_point = 214)
t
This framework allows for a full and efficient exploration of the entire design space.
In addition, these concepts don't just apply to binary addition. They apply to a wide range of hardware operations.





