![]()
![]()





![]()
SlickML🧞 : Slick Machine Learning in Python
Explore Releases
🧠 SlickML🧞 Philosophy
SlickML is an open-source machine learning library written in Python aimed at accelerating the
experimentation time for ML applications with tabular data while maximizing the amount of information
can be inferred. Data Scientists' tasks can often be repetitive such as feature selection, model
tuning, or evaluating metrics for classification and regression problems. We strongly believe that a
good portion of the tasks based on tabular data can be addressed via gradient boosting and generalized
linear models1. SlickML provides Data Scientists
with a toolbox to quickly prototype solutions for a given problem with minimal code while maximizing
the amount of information that can be inferred. Additionally, the prototype solutions can be easily
promoted and served in production with our recommended recipes via various model serving frameworks
including ZenML, BentoML,
and Prefect. More details coming soon
📖 Documentation
🛠 Installation
To begin with, install Python version >=3.8,<3.11 and to install the library
from PyPI simply run
pip install slickml
or if you are a python poetry user, simply run
poetry add slickml
gfortran) is also required to build the package. If you do not have gcc installed, the following commands depending on your operating system will take care of this requirement.
# Mac Users
brew install gcc
# Linux Users
sudo apt install build-essential gfortran
The SlickML CLI tool behaves similarly to many other CLIs for basic features. In order to find out
which version of SlickML you are running, simply run
slickml --version
🐍 Python Virtual Environments
In order to avoid any potential conflicts with other installed Python packages, it is
recommended to use a virtual environment, e.g. python poetry, python virtualenv, pyenv virtualenv, or conda environment. Our recommendation is to use python-poetry
📌 Quick Start
Feature Selection pipeline with embedded Cross-Validation and Feature-Importance visualization:
from slickml.feautre_selection import XGBoostFeatureSelector
xfs = XGBoostFeatureSelector()
xfs.fit(X, y)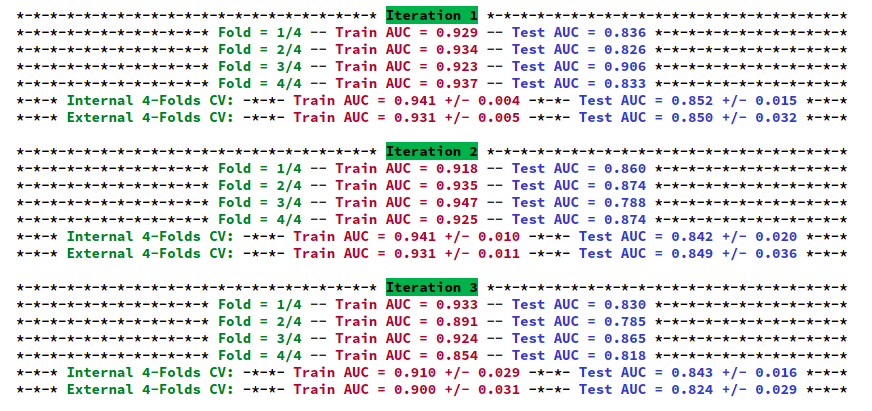
xfs.plot_cv_results()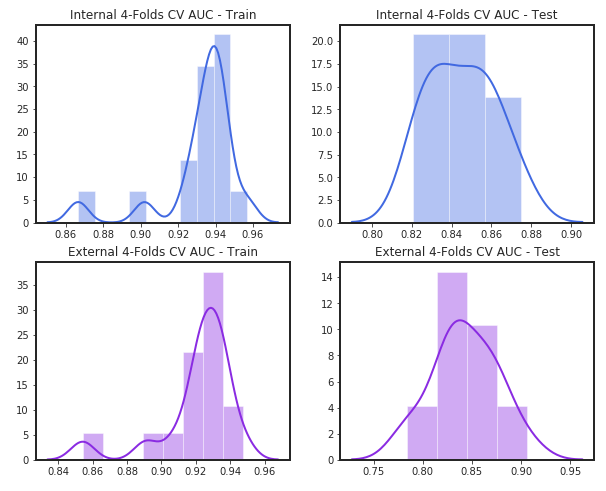
xfs.plot_frequency()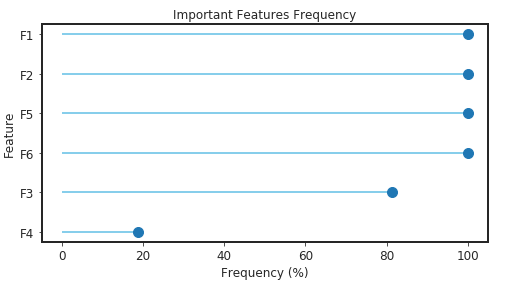
tuned hyper-parameter with Bayesian Optimization:
from slickml.optimization import XGBoostBayesianOptimizer
xbo = XGBoostBayesianOptimizer()
xbo.fit(X_train, y_train)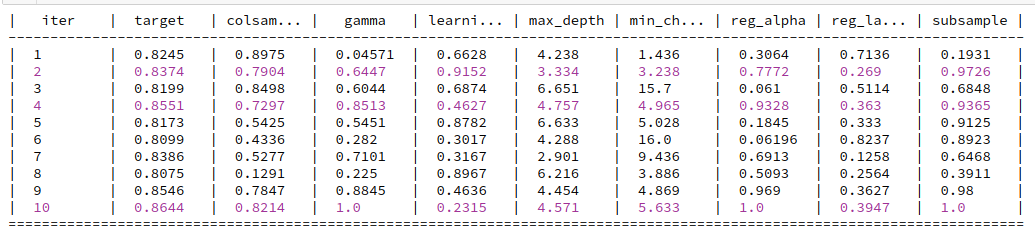
best_params = xbo.get_best_params()
best_params
{"colsample_bytree": 0.8213916662259918,
"gamma": 1.0,
"learning_rate": 0.23148232373451072,
"max_depth": 4,
"min_child_weight": 5.632602921054691,
"reg_alpha": 1.0,
"reg_lambda": 0.39468801734425263,
"subsample": 1.0
}XGBoostCV Classifier with Cross-Validation, Feature-Importance, and Shap visualizations:
from slickml.classification import XGBoostCVClassifier
clf = XGBoostCVClassifier(params=best_params)
clf.fit(X_train, y_train)
y_pred_proba = clf.predict_proba(X_test)
clf.plot_cv_results()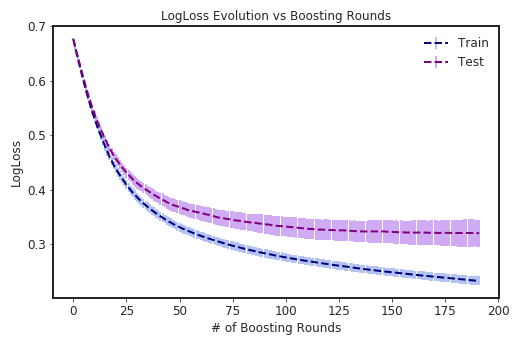
clf.plot_feature_importance()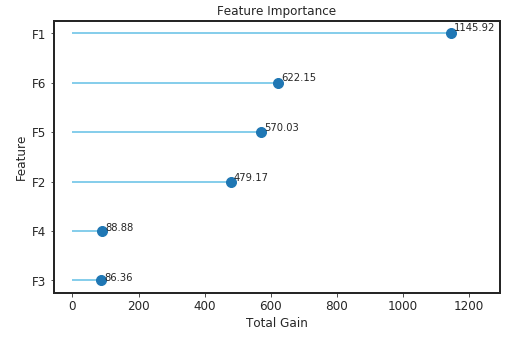
clf.plot_shap_summary(plot_type="violin")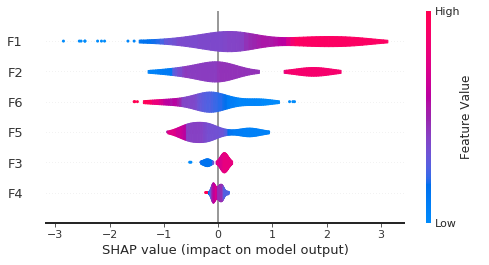
clf.plot_shap_summary(plot_type="layered_violin", layered_violin_max_num_bins=5)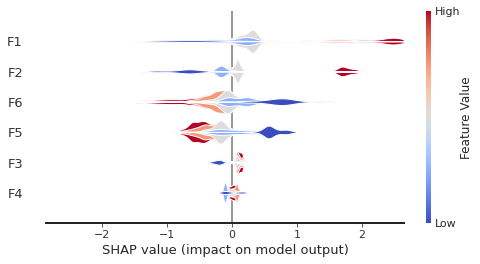
clf.plot_shap_waterfall()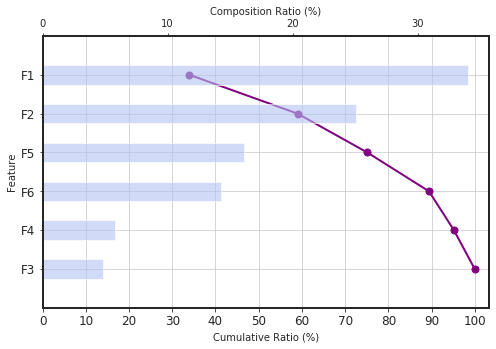
GLMNetCV Classifier with Cross-Validation and Coefficients visualizations:
from slickml.classification import GLMNetCVClassifier
clf = GLMNetCVClassifier(alpha=0.3, n_splits=4, metric="auc")
clf.fit(X_train, y_train)
y_pred_proba = clf.predict_proba(X_test)
clf.plot_cv_results()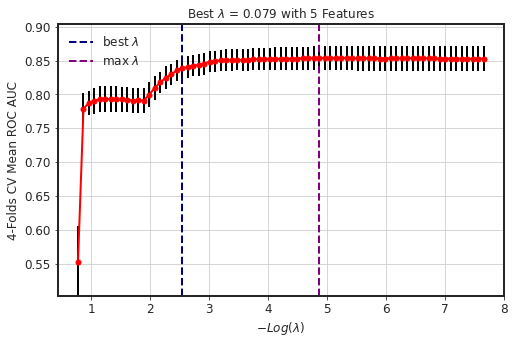
clf.plot_coeff_path()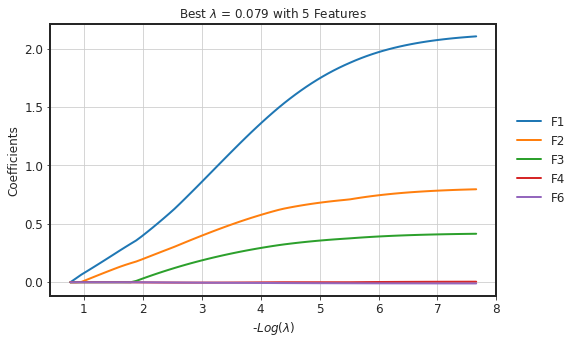
binary classification metrics based on multiple thresholds:
from slickml.metrics import BinaryClassificationMetrics
clf_metrics = BinaryClassificationMetrics(y_test, y_pred_proba)
clf_metrics.plot()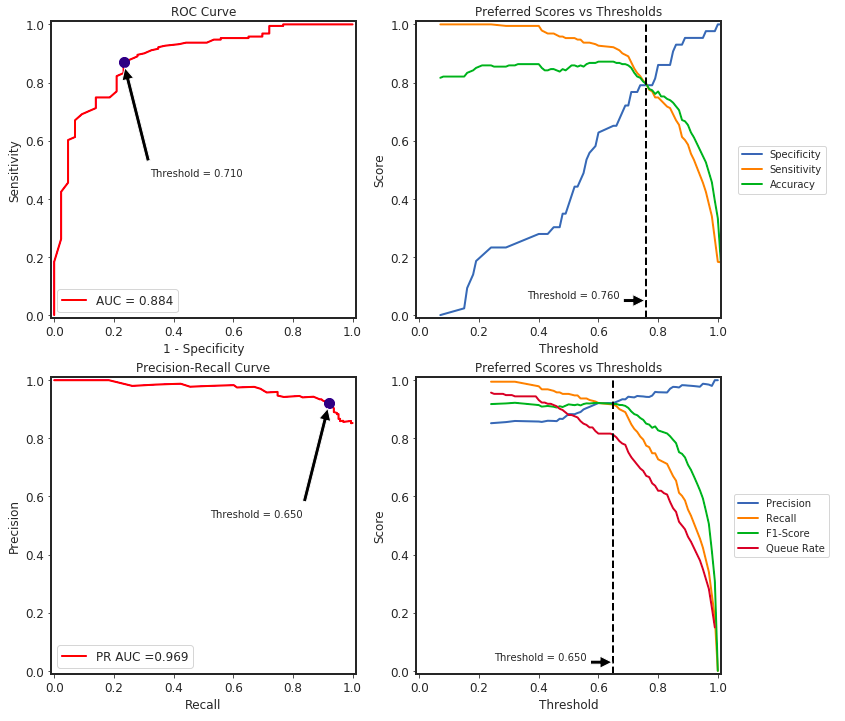
regression metrics:
from slickml.metrics import RegressionMetrics
reg_metrics = RegressionMetrics(y_test, y_pred)
reg_metrics.plot()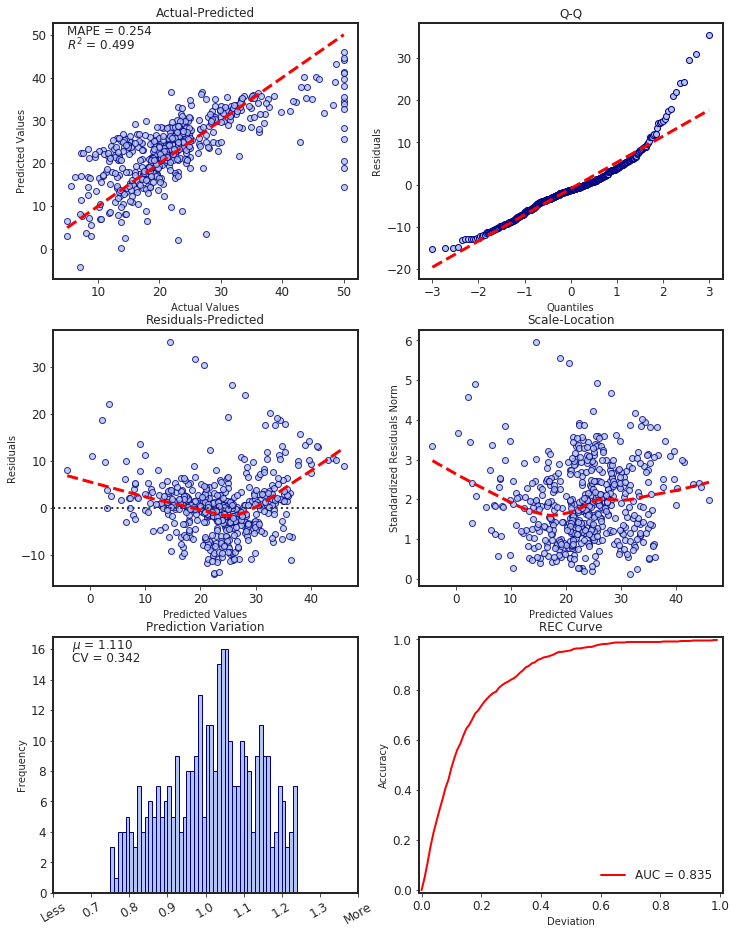
🧑💻 🤝 Contributing to SlickML🧞
You can find the details of the development process in our Contributing guidelines. We strongly believe that reading and following these guidelines will help us make the contribution process easy and effective for everyone involved

❓ 🆘 📲 Need Help?
Please join our Slack Channel to interact directly with the core team and our small community. This is a good place to discuss your questions and ideas or in general ask for help
📚 Citing SlickML🧞
If you use SlickML in an academic work
Bibtex Entry:
@software{slickml2020,
title={SlickML: Slick Machine Learning in Python},
author={Tahmassebi, Amirhessam and Smith, Trace},
url={https://github.com/slickml/slick-ml},
version={0.2.0},
year={2021},
}
@article{tahmassebi2021slickml,
title={Slickml: Slick machine learning in python},
author={Tahmassebi, Amirhessam and Smith, Trace},
journal={URL available at: https://github. com/slickml/slick-ml},
year={2021}
}


