A Unifying and Rapidly Deployable Toolbox for Pre-trained Model Reuse
English | 中文
ZhiJian (执简驭繁) is a comprehensive and user-friendly PyTorch-based Model Reuse toolbox for leveraging foundation pre-trained models and their fine-tuned counterparts to extract knowledge and expedite learning in real-world tasks.
The rapid progress in deep learning has led to the emergence of numerous open-source Pre-Trained Models (PTMs) on platforms like PyTorch, TensorFlow, and HuggingFace Transformers. Leveraging these PTMs for specific tasks empowers them to handle objectives effectively, creating valuable resources for the machine-learning community. Reusing PTMs is vital in enhancing target models' capabilities and efficiency, achieved through adapting the architecture, customizing learning on target data, or devising optimized inference strategies to leverage PTM knowledge.

🔥 To facilitate a holistic consideration of various model reuse strategies, ZhiJian categorizes model reuse methods into three sequential modules: Architect, Tuner, and Merger, aligning with the stages of model preparation, model learning, and model inference on the target task, respectively. The provided interface methods include:
Architect Module [Click to Expand]The Architect module involves modifying the pre-trained model to fit the target task, and reusing certain parts of the pre-trained model while introducing new learnable parameters with specialized structures.
Linear Probing & Partial-k, How transferable are features in deep neural networks? In: NeurIPS'14. [Paper] [Code]





Scaling & Shifting, Scaling & Shifting Your Features: A New Baseline for Efficient Model Tuning. In: NeurIPS'22. [Paper] [Code]

AdaptFormer, AdaptFormer: Adapting Vision Transformers for Scalable Visual Recognition. In: NeurIPS'22. [Paper] [Code]

BitFit, BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models. In: ACL'22. [Paper] [Code]



Tuner Module [Click to Expand]The Tuner module focuses on training the target model with guidance from pre-trained model knowledge to expedite the optimization process, e.g., via adjusting objectives, optimizers, or regularizers.
Knowledge Transfer, NeC4.5: neural ensemble based C4.5. In: IEEE Trans. Knowl. Data Eng. 2004. [Paper] [Code]

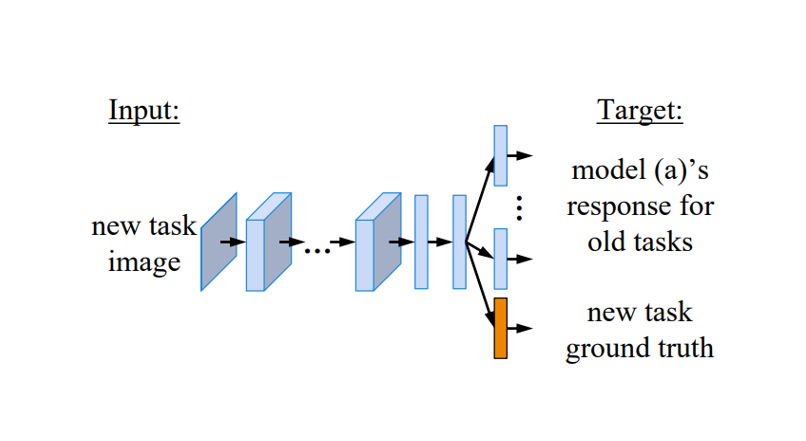
FSP, A Gift from Knowledge Distillation: Fast Optimization, Network Minimization and Transfer Learning. In: CVPR'17. [Paper] [Code]

NST, Like What You Like: Knowledge Distill via Neuron Selectivity Transfer. In: CVPR'17. [Paper] [Code]
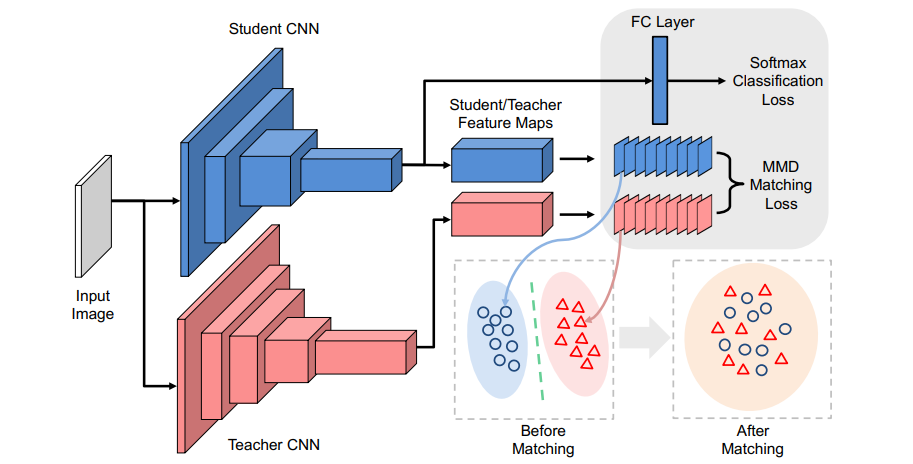





L2 penalty / L2-SP, Explicit Inductive Bias for Transfer Learning with Convolutional Networks. In: ICML'18. [Paper] [Code]

Spectral Norm, Spectral Normalization for Generative Adversarial Networks. In: ICLR'18. [Paper] [Code]

BSS, Catastrophic Forgetting Meets Negative Transfer: Batch Spectral Shrinkage for Safe Transfer Learning. In: NeurIPS'19. [Paper] [Code]

DELTA, DELTA: DEep Learning Transfer using Feature Map with Attention for Convolutional Networks. In: ICLR'19. [Paper] [Code]



Merger Module [Click to Expand]The Merger module influences the inference phase by either reusing pre-trained features or incorporating adapted logits from the pre-trained model.

SimpleShot, SimpleShot: Revisiting Nearest-Neighbor Classification for Few-Shot Learning. In: CVPR'19. [Paper] [Code]

Head2Toe, Head2Toe: Utilizing Intermediate Representations for Better Transfer Learning. In: ICML'22. [Paper] [Code]

VQT, Visual Query Tuning: Towards Effective Usage of Intermediate Representations for Parameter and Memory Efficient Transfer Learning. In: CVPR'23. [Paper] [Code]
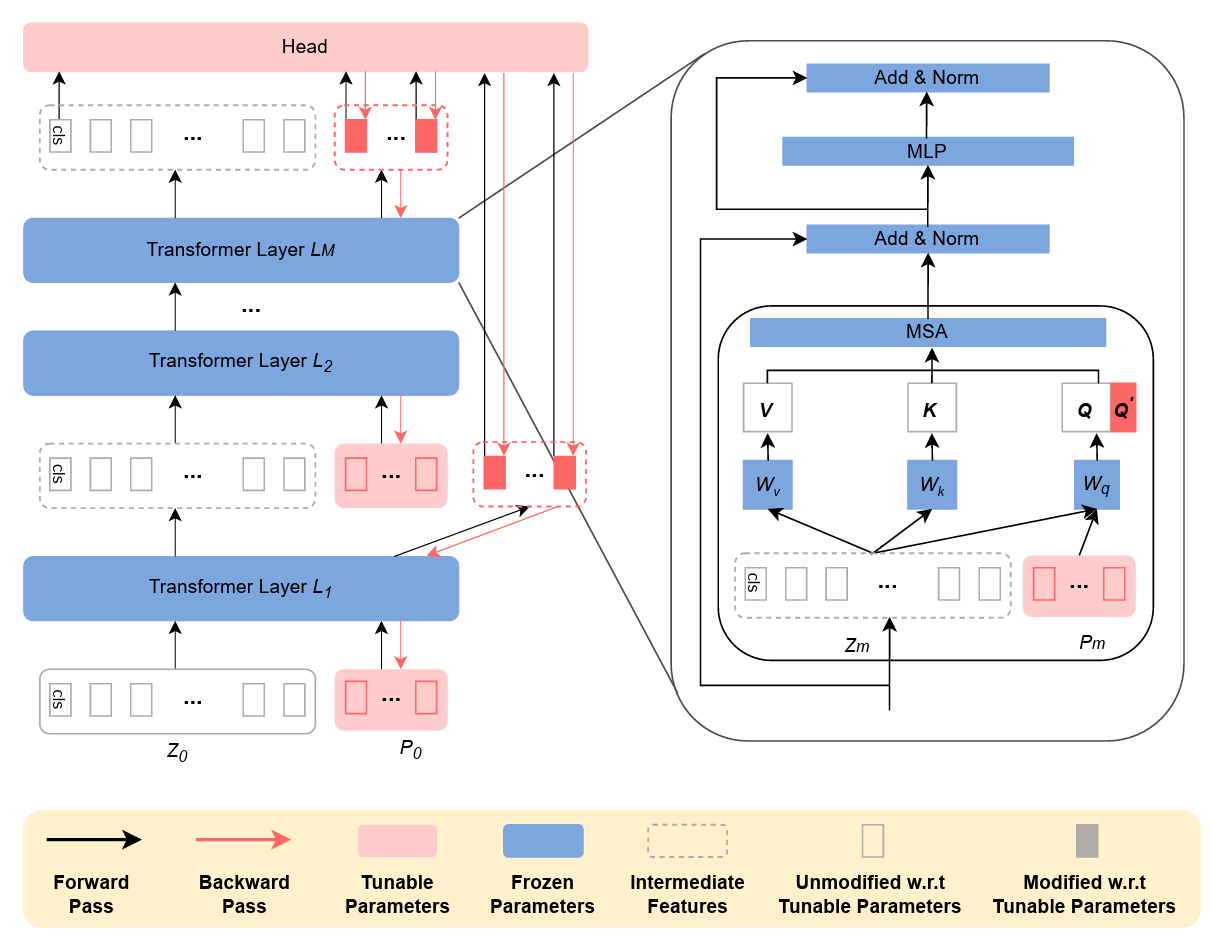

Model Soup Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time. In: ICML'22. [Paper] [Code]



REPAIR REPAIR: REnormalizing Permuted Activations for Interpolation Repair. In: ICLR'23. [Paper] [Code]



💡 ZhiJian also has the following highlights:
-
Support reuse of various pre-trained model zoo, including:
- PyTorch Torchvision; OpenAI CLIP; 🤗Hugging Face PyTorch Image Models (timm), Transformers
- Other popular projects, e.g., vit-pytorch (stars 14k).
- Large Language Model, including baichuan, LLaMA, and BLOOM.
-
Extremely easy to get started and customize
- Get started with a 10 minute blitz
- Customize datasets and pre-trained models with step-by-step instructions
- Feel free to create a novel approach for reusing pre-trained model
- Get started with a 10 minute blitz
- Concise things do big
"ZhiJian" in Chinese means handling complexity with concise and efficient methods. Given the variations in pre-trained models and the deployment overhead of full parameter fine-tuning, ZhiJian represents a solution that is easily reusable, maintains high accuracy, and maximizes the potential of pre-trained models.
“执简驭繁”的意思是用简洁高效的方法驾驭纷繁复杂的事物。“繁”表示现有预训练模型和复用方法种类多、差异大、部署难,所以取名"执简"的意思是通过该工具包,能轻松地驾驭模型复用方法,易上手、快复用、稳精度,最大限度地唤醒预训练模型的知识。
🕹️ Quick Start
-
An environment with Python 3.7+ from conda, venv, or virtualenv.
-
Install ZhiJian using pip:
$ pip install zhijian
- [Option] Install with the newest version through GitHub:
$ pip install git+https://github.com/ZhangYikaii/LAMDA-ZhiJian.git@main --upgrade
- [Option] Install with the newest version through GitHub:
-
Open your python console and type
import zhijian print(zhijian.__version__)
If no error occurs, you have successfully installed ZhiJian.
Documentation
📚 The tutorials and API documentation are hosted on ZhiJian.readthedocs.io
Why ZhiJian?

| Related Library | GitHub Stars | # of Alg.(1) | # of Model(1) | # of Dataset(1) | # of Fields(2) | LLM Supp. | Docs. | Last Update |
| PEFT |

|
6 | ~15 | ➖(3) | 1(a) | ✔️ | ✔️ |

|
| adapter-transformers |

|
10 | ~15 | ➖(3) | 1(a) | ❌ | ✔️ |

|
| LLaMA-Efficient-Tuning |

|
4 | 5 | ~20 | 1(a) | ✔️ | ❌ |

|
| Knowledge-Distillation-Zoo |

|
20 | 2 | 2 | 1(b) | ❌ | ❌ |

|
| Easy Few-Shot Learning |

|
10 | 3 | 2 | 1(b) | ❌ | ❌ |

|
| Model soups |

|
3 | 3 | 5 | 1(c) | ❌ | ❌ |

|
| Git Re-Basin |

|
3 | 5 | 4 | 1(c) | ❌ | ❌ |

|
| ZhiJian | 🙌 | 30+ | ~50 | 19 | 3(a,b,c) | ✔️ | ✔️ |

|
(1): access date: 2023-08-05 (2): fields for (a) Architect; (b) Tuner; (c) Merger;
📦 Reproducible SoTA Results
ZhiJian fixed the random seed to ensure reproducibility of the results, with only minor variations across different devices.
VTAB of Multi-Reuse-Tasks Challenge
We develop a robust classification challenge called VTAB-M (Visual Task Adaptation Benchmark for Multi-Reuse-Tasks), building upon the VTAB. This challenge involves tackling a diverse set of 18 visual tasks concurrently, while harnessing the power of pre-trained knowledge. The primary objective is to equip models with versatile capabilities that span across natural, specialized, and structured visual domains.
The challenge incorporates datasets including CIFAR-100, CLEVR-Count, CLEVR-Distance, Caltech101, DTD, Diabetic-Retinopathy, Dmlab, EuroSAT, KITTI, Oxford-Flowers-102, Oxford-IIIT-Pet, PatchCamelyon, RESISC45, SVHN, dSprites-Location, dSprites-Orientation, smallNORB-Azimuth, and smallNORB-Elevation. Following the VTAB-1k standards, we sample a training set consisting of 1,000 samples from each dataset. The comprehensive model evaluation is conducted using the entire test data. VTAB-M serves as a comprehensive evaluation framework that assessing models' generalization and adaptation across diverse visual tasks. It pushes the pre-trained models to become more versatile and proficient through reuse methods.
More results will be released gradually in upcoming updates. Please stay tuned for more information.
| Method | Tuned Params | Mixed Mean | Caltech101 | CIFAR-100 | CLEVR-Count | CLEVR-Distance | Diabetic-Retinopathy | Dmlab | dSprites-Location | dSprites-Orientation | DTD | EuroSAT | KITTI | Oxford-Flowers-102 | Oxford-IIIT-Pet | PatchCamelyon | RESISC45 | smallNORB-Azimuth | smallNORB-Elevation | SVHN |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Adapter |
0.73/86.53(M) | 57.14 | 84.16 | 66.74 | 30.43 | 22.97 | 75.92 | 46.29 | 3.76 | 26.47 | 68.03 | 95.13 | 49.09 | 98.63 | 91.47 | 79.21 | 82.25 | 7.99 | 23.20 | 76.71 |
LoRA |
0.71/86.51(M) | 57.61 | 84.75 | 63.92 | 33.25 | 27.85 | 76.37 | 44.90 | 4.54 | 24.72 | 68.56 | 94.33 | 50.91 | 98.80 | 91.66 | 82.57 | 82.71 | 5.92 | 27.00 | 74.30 |
VPT / Deep |
0.45/86.24(M) | 53.12 | 83.15 | 52.39 | 23.49 | 20.67 | 75.13 | 39.37 | 2.84 | 23.06 | 66.12 | 93.13 | 42.33 | 97.82 | 90.00 | 77.45 | 79.75 | 7.65 | 18.02 | 63.87 |
Linear Probing |
0.42/86.22(M) | 48.59 | 80.93 | 37.15 | 14.07 | 22.27 | 74.68 | 35.32 | 3.29 | 18.51 | 60.69 | 88.72 | 40.08 | 97.59 | 88.09 | 79.36 | 72.98 | 7.42 | 15.09 | 38.34 |
Partial-1 |
7.51/86.22(M) | 51.60 | 81.87 | 42.01 | 25.50 | 24.34 | 75.20 | 39.39 | 2.08 | 24.29 | 63.94 | 91.37 | 34.60 | 97.82 | 89.48 | 79.50 | 77.57 | 7.65 | 21.85 | 50.35 |
Contributing
ZhiJian is currently in active development, and we warmly welcome any contributions aimed at enhancing capabilities. Whether you have insights to share regarding pre-trained models, data, or innovative reuse methods, we eagerly invite you to join us in making ZhiJian even better. If you want to submit your valuable contributions, please click here.
Citing ZhiJian
@misc{zhang2023zhijian,
title={ZhiJian: A Unifying and Rapidly Deployable Toolbox for Pre-trained Model Reuse},
author={Yi-Kai Zhang and Lu Ren and Chao Yi and Qi-Wei Wang and De-Chuan Zhan and Han-Jia Ye},
year={2023},
eprint={2308.09158},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
@misc{zhijian2023,
author = {ZhiJian Contributors},
title = {LAMDA-ZhiJian},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/zhangyikaii/LAMDA-ZhiJian}}
}

