
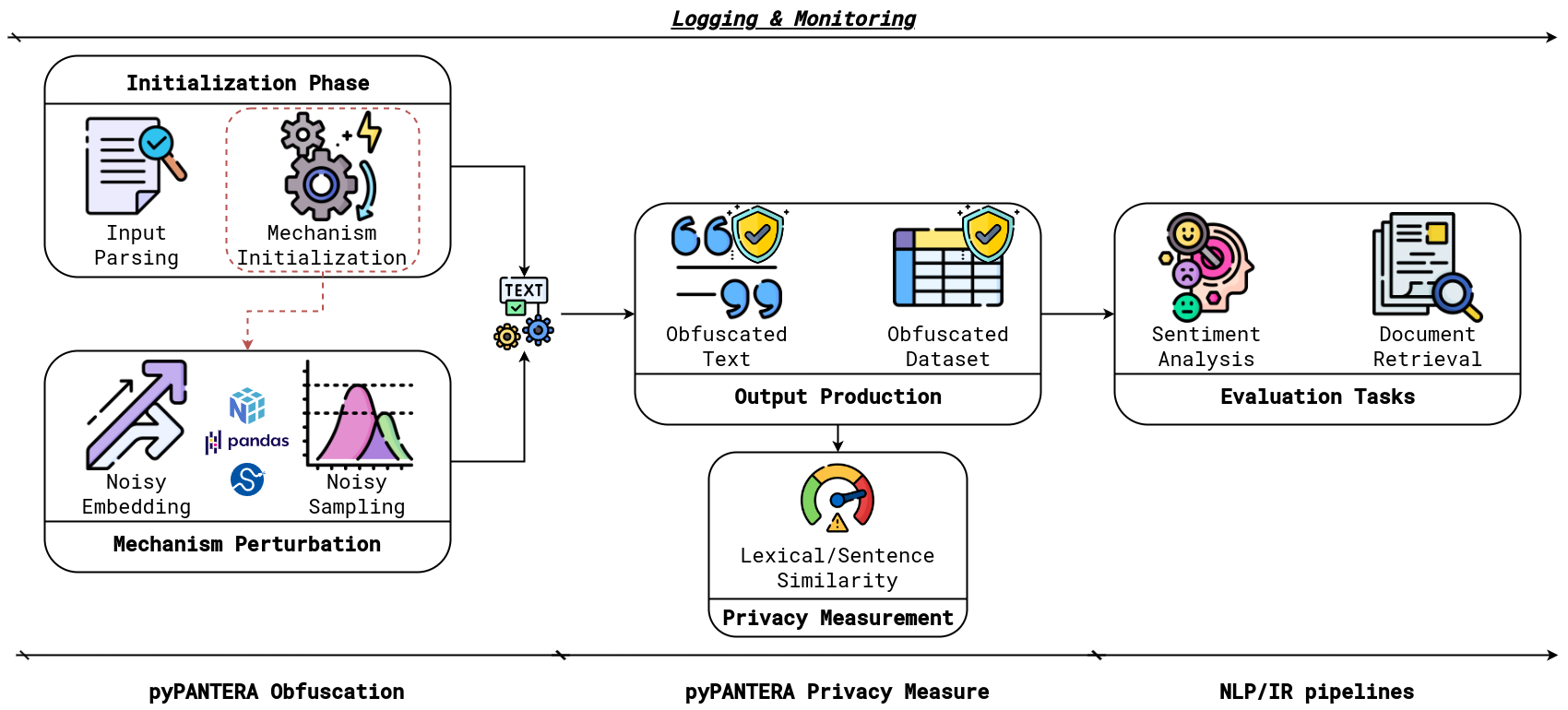
pyPANTERA1 is a Python package that provides a simple interface to obfuscate natural language text. It is designed to help privacy practitioners implement, reproduce and test State-of-the-Art techniques for natural language obfuscation that implements
The package offers a combination of natural language processing and mathematical transformations to obfuscate natural language text. It replaces the original string texts with their obfuscated versions, ensuring that the obfuscated text is not directly related to the original text. The obfuscation is performed using word embeddings and word sampling mechanisms, and it is designed to be
We provide also a virtual environment to run the package:
- You can create the virtual environment virtualEnvPyPANTERA using the
environment.ymlfile, and running in your terminal:
conda env create -f environment.yml- Once the environment is created, you can verify that it is installed by running:
conda env list- Finally, you can activate the virtual environment by running:
conda activate virtualEnvPyPANTERAIn the requirements.txt file, you can find the list of the requirements used by pyPANTERA.
pyPANTERA is designed to be easy to use and accessible for everyone. You can install it using pip:
pip install pypanteraOnce installed, you can use it in your Python code by importing it as follows:
import pypanterapyPANTERA implements current State-of-the-Art mechanisms that use
The mechanisms implemented in pyPANTERA are divided into two categories:
-
Word Embeddings Perturbation: This mechanism uses word embeddings to obfuscate the text. It replaces the original word embeddings with a perturbated version of them. Such perturbation is done by adding a statistical noise depending on the mechanism design. The mechanisms implemented are the following:
- Calibrated Multivariate Perturbations (CMP): Addition of spherical noise to the word embeddings. See reference 2 for more information.
- Mahalanobis Perturbations (Mahalanobis): Addition of elliptical noise to the word embeddings. See reference 3 for more information.
- Vickrey family of mechanisms (Vickrey): Perturbation is performed using a threshold value to select the nearest perturbed embedding of a term. See reference 4 for more information.
-
Word Sampling Perturbation: This mechanism uses word sampling to obfuscate the text. The mechanism computes for each word in the text a list of neighbouring words with the respective scores, then it samples a substitution candidate by basing such sampling on the scores of the neighbouring terms and the privacy budget
$\varepsilon$ . The mechanisms implemented are the following:- Customized Text (CusText): Sampling of the substitution candidate from the neighbouring
$k$ words of the original word. See reference 5 for more information. - Sanitization Text (SanText): Sampling of the substitution candidate from the neighbouring words of the original word. See reference 6 for more information.
- Truncated Exponential Mechanism (TEM): Sampling of the substitution candidate using the exponential mechanism with the scores of the neighbouring words. See reference 7 for more information.
- Customized Text (CusText): Sampling of the substitution candidate from the neighbouring
We provide a simple example to show how pyPANTERA works with a concrete example. We suggest using the prepared virtual environment to run the example and the base script testTASK.py to run the obfuscation pipeline, i.e, ObfuscationIR and ObfuscationSentiment.
python testObfuscationIR.py --embPath /absolute/path/to/embeddings --inputPath /absolute/path/to/input/data --outputPath /absolute/path/to/output/data --mechanism MECHANISM --epsilon EPSILON --task TASK --numberOfObfuscations N --PARAMETERS
The script will run the obfuscation pipeline using the embeddings in the path provided in the --embPath | -eP argument, the input data in the path provided in the --inputPath | -i argument, and --outputPath | -o is used as output path for storing the results. If --outputPath is not provided, it creates a folder ./results/task/mechanism/ to save the obfuscated data frames.
pyPANTERA requires that the input data is a CSV file with a column named text that contains the text to obfuscate and an id to keep track of the correspondence between original and obfuscated versions.
The --task | -tk argument is used to specify the future task that you want to perform using the new obfuscated texts. The --epsilon | -e argument is used to specify the epsilon value for the differential privacy mechanism. The --mechanism | -m argument is used to specify the mechanism to use for the obfuscation. The --numberOfObfuscations | -n argument is used to specify the number of obfuscations to perform for the same text. Finally, the --PARAMETERS are the parameters for the mechanism that you want to use. We provide a specific list of parameters for each mechanism in the following section.
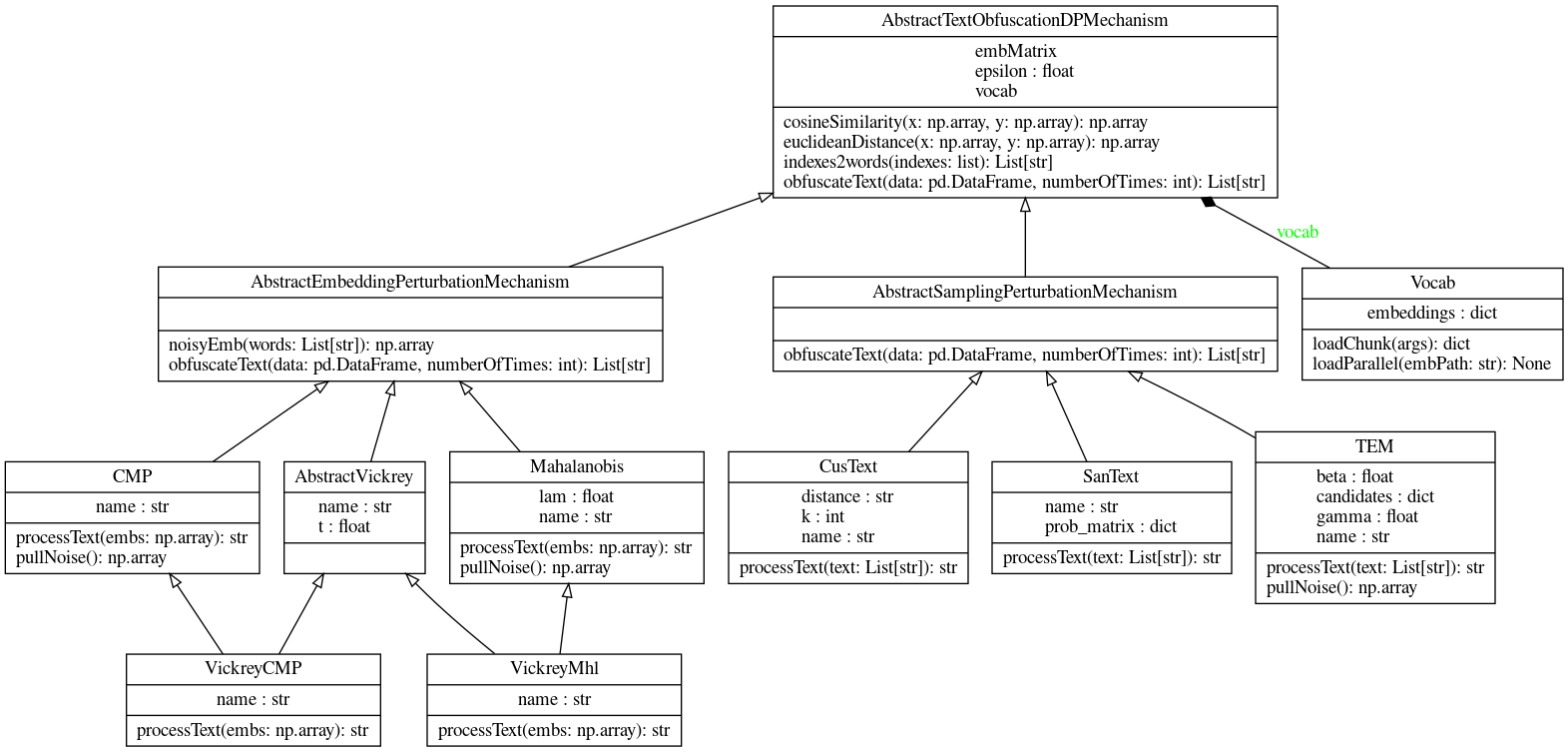
The UML diagram of the pyPANTERA source code is displayed below:
The script test.py has the following parameters, based on the mechanism parameters that you want to use:
-
General Parameters:
-
--embPath | -eP: The path to the word embeddings file (default str: None, required) -
--inputPath | -i: The path to the input data file (default str: None, required) -
--outputPath | -o: The path to the output data file (default str: None) -
--task | -tk: The future task that you want to perform using the new obfuscated texts (default str: 'retrieval') -
--epsilon | -e: The epsilon value for the differential privacy mechanism (default List[float]: [1.0, 5.0, 10.0, 12.5, 15.0, 17.5, 20.0, 50.0]) -
--mechanism | -m: The mechanism to use for the obfuscation (default str: 'CMP', choices: ['CMP', 'Mahalanobis', 'VickreyCMP', 'VickreyMhl', 'CusText', 'SanText', 'TEM']) -
--numberOfObfuscations | -n: The number of obfuscations to perform for the same text (default int: 1)
-
-
CMP: The parameters for the CMP mechanism are only the general ones.
-
Mahalanobis: The parameters for the Mahalanobis mechanism are the following:
-
--lam: The lambda value for the Mahalanobis norm (default float: 1)
-
-
VickreyCMP/VickreyMhl: The parameters for the Vickrey mechanism are the following:
-
--t: The threshold value for the Vickrey mechanism (default float: 0.75). Eventually, if you use theVickreyMhlmechanism, you can also use the--lamparameter to set the lambda value for the Mahalanobis norm (default float: 1)
-
-
CusText: The parameters for the CusText mechanism are the following:
-
--k: The number of neighbouring words to consider for the sampling (default int: 10) -
--distance | -d: The distance metric to use for the sampling (default str: 'Euclidean')
-
-
SanText: The parameters for the SanText mechanism are only the general ones.
-
TEM: The parameters for the TEM mechanism are the following:
-
--beta: The beta value for the exponential mechanism (default float: 0.001)
-
Suppose you want to run the obfuscation pipeline using the CMP mechanism with the embeddings in the path ./embeddings/glove.6B.50d.txt, the input data in the path ./data/input.csv, and the output data in the path ./data/output.csv, for all the default values of
python test.py --embPath /embeddings/glove.6B.50d.txt --inputPath /data/input.csv --outputPath /data/output/ --mechanism CMPTo enhance the clarity of how pyPANTERA works, we add a toy Python Notebook to simulate some of the obfuscation implemented.
The following Table reports the experimental parameters used for obtaining the obfuscated texts used in the experiments presented in the paper.
| Embedding Perturbation Mechanisms | Sampling Perturbation Mechanisms | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
Using the test.py script running CMP, embeddings 300d GloVe with the default parameters, we obtain the following results for the DL'19 queries dataset (overview of the first two rows, for
| id | text | obfuscatedText | mechansim | epsilon |
|---|---|---|---|---|
| 156493 | do goldfish grow | hipc householder 1976-1983 | CMP | 1 |
| 1110199 | what is wifi vs bluetooth | 25-june nonsubscribers trimet edema --- | CMP | 1 |
| id | text | obfuscatedText | mechansim | epsilon |
|---|---|---|---|---|
| 156493 | do goldfish grow | foil householder scotland | CMP | 5 |
| 1110199 | what is wifi vs bluetooth | galangal naat trimet edema --- | CMP | 5 |
| id | text | obfuscatedText | mechansim | epsilon |
|---|---|---|---|---|
| 156493 | do goldfish grow | do goldfish grow | CMP | 10 |
| 1110199 | what is wifi vs bluetooth | out salvage terrestrial 7-3 bluetooth | CMP | 10 |
The package is released under the GNU GENERAL PUBLIC LICENSE Version 3, 29 June 2007. You can find the full text of the license in the LICENSE file.
Footnotes
-
Prompt for DALL-E pyPANTER generation: "A cute panther sitting beside the Python programming language symbol. The panther should have big, expressive eyes and a friendly demeanor, sitting in." ↩
-
Privacy- and Utility-Preserving Textual Analysis via Calibrated Multivariate Perturbations (Feyisetan et al., In Proceedings of the International Conference on Web Search and Data Mining, 2020) ↩
-
A Differentially Private Text Perturbation Method Using Regularized Mahalanobis Metric (Xu et al., In Proceedings of the Second Workshop on Privacy in NLP, 2020) ↩
-
On a Utilitarian Approach to Privacy Preserving Text Generation (Xu et al., In Proceedings of the Third Workshop on Privacy in Natural Language Processing, 2021) ↩
-
A Customized Text Sanitization Mechanism with Differential Privacy (Chen et al., In Findings of the Association for Computational Linguistics, 2023) ↩
-
Differential Privacy for Text Analytics via Natural Text Sanitization (Yue et al., In Findings of the Association for Computational Linguistics, 2021) ↩
-
TEM: High Utility Metric Differential Privacy on Text (Carvalho et al., In Proceedings of the 2023 SIAM International Conference on Data Mining, 2023) ↩
