SQLPipe - Easy way to build SQL pipelines
With SQLPipe it is possible to create a full pipeline and orchestrate dependencies in a simplified way using SQL. The task management uses the asyncio library, so execution is done with the python coroutine system for parallel executions.
 Installation:
Installation:
pip install sqlpipe
Basic Example
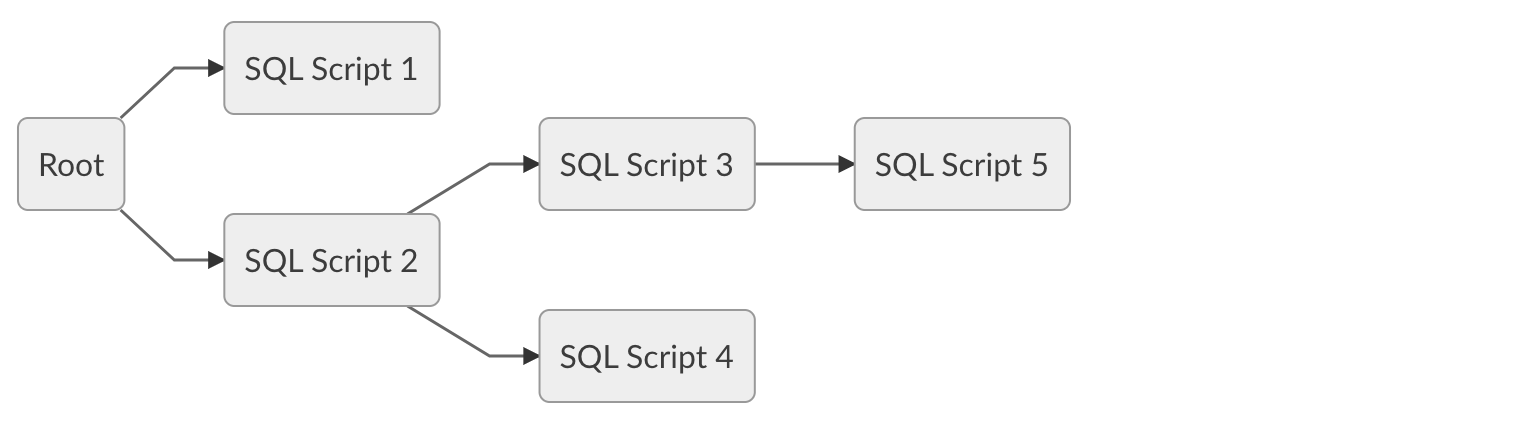
Using SqlPipeBuilder. Once the object has been instantiated, use the add_task method to add the scripts to be executed, you must specify a different id for each task, if one task depends on another, use the parent_id parameter to configure the dependency.
from sqlpipe import SqlPipeBuilder
con_str = 'postgres://user:pass@host:port/dbname'
pipe = SqlPipeBuilder(con_str, connections_limit=5)
# Add custom script
pipe.add_task(id='id_2', script='truncate table t1;', parent_id='id_1')
# Add SQL file script
pipe.add_task(id='id_1', script='queries/tables/t1.sql', file=True)
# Add all .sql in directory
pipe.map_directory('queries')
# Execute all pipeline
pipe.execute()
# Start from specifc task
pipe.execute('id_2')
Using CLI
Call the CLI and pass the directory (-d or --directory) parameter, after that all .sql files in the directory and subdirectories will be started. To configure a dependency just put the dependency in a comment on script file, example /* @parent=my-parent-task */.
python -m sqlpipe -d queries
It's possible to call specific task passing the task parameter (-t or --task).
python -m sqlpipe -d queries -t task-id
Supported Databases
- MySQL
- PostgreSQL
- Redshift
Licence
